Dowód Chi do kwadratu lub chi-kwadrat (χdwa, gdzie χ to grecka litera zwana „chi”) służy do określenia zachowania pewnej zmiennej, a także gdy chcesz wiedzieć, czy dwie lub więcej zmiennych jest statystycznie niezależnych.
Aby sprawdzić zachowanie zmiennej, wywoływany jest test, który ma zostać wykonany test dopasowania chi-kwadrat. Aby dowiedzieć się, czy dwie lub więcej zmiennych jest statystycznie niezależnych, wywoływany jest test chi kwadrat niezależności, nazywany również przypadkowość.
Testy te są częścią statystycznej teorii decyzji, w której badana jest populacja i podejmowane decyzje na jej temat, analizując jedną lub więcej pobranych z niej próbek. Wymaga to przyjęcia pewnych założeń dotyczących zmiennych, tzw hipoteza, co może być prawdą lub nie.
Istnieje kilka testów, które porównują te przypuszczenia i określają, które są prawidłowe, z pewnym marginesem pewności, w tym test chi-kwadrat, który można zastosować do porównania dwóch i więcej populacji..
Jak zobaczymy, dwa typy hipotez są zwykle podnoszone na temat jakiegoś parametru populacji w dwóch próbach: hipoteza zerowa, zwana Hlub (próbki są niezależne) i hipotezę alternatywną, oznaczoną jako H.1, (próbki są skorelowane), co jest przeciwieństwem tego.
Indeks artykułów
Test chi-kwadrat stosuje się do zmiennych opisujących takie cechy, jak płeć, stan cywilny, grupa krwi, kolor oczu i różnego rodzaju preferencje.
Test jest przeznaczony, gdy chcesz:
-Sprawdzenie, czy rozkład jest odpowiedni do opisania zmiennej, która jest nazywana Dobroć dopasowania. Za pomocą testu chi-kwadrat można dowiedzieć się, czy istnieją istotne różnice między wybranym rozkładem teoretycznym a obserwowanym rozkładem częstotliwości..
-Wiedz, czy dwie zmienne X i Y są niezależne ze statystycznego punktu widzenia. Jest to znane jako test niezależności.
Ponieważ jest stosowany do zmiennych jakościowych lub kategorialnych, test chi-kwadrat jest szeroko stosowany w naukach społecznych, zarządzaniu i medycynie..
Istnieją dwa ważne wymagania, aby poprawnie go zastosować:
-Dane muszą być pogrupowane według częstotliwości.
-Próbka musi być dostatecznie duża, aby rozkład chi-kwadrat był prawidłowy, w przeciwnym razie jej wartość jest przeszacowana i prowadzi do odrzucenia hipotezy zerowej, gdy nie powinno tak być..
Ogólna zasada jest taka, że jeśli w zgrupowanych danych pojawia się częstotliwość o wartości mniejszej niż 5, nie jest ona używana. Jeśli więcej niż jedna częstotliwość jest mniejsza niż 5, należy je połączyć w jedną, aby uzyskać częstotliwość o wartości liczbowej większej niż 5.
χdwa jest to ciągły rozkład prawdopodobieństw. W rzeczywistości istnieją różne krzywe, w zależności od parametru k nazywa stopnie swobody zmiennej losowej.
Jego właściwości to:
-Powierzchnia pod krzywą jest równa 1.
-Wartości χdwa są pozytywne.
-Dystrybucja jest asymetryczna, to znaczy ma odchylenie.
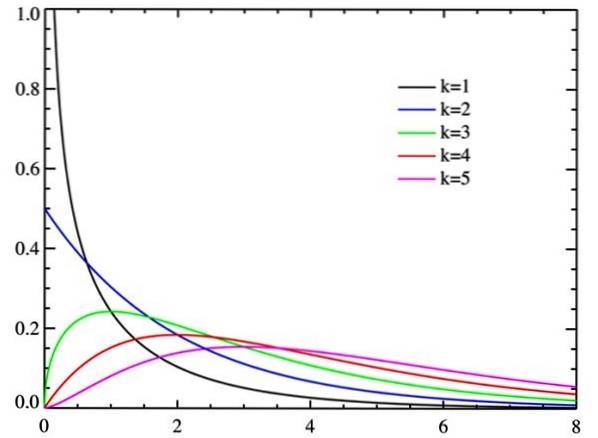
Wraz ze wzrostem stopni swobody rozkład chi-kwadrat zmierza w kierunku normalności, jak widać na rysunku.
Dla danego rozkładu stopnie swobody są określane za pomocą tabela awaryjna, która jest tabelą, w której zapisywane są obserwowane częstości zmiennych.
Jeśli stół ma fa rzędy i do kolumny, wartość k to jest:
k = (f - 1) ⋅ (c - 1)
Gdy test chi-kwadrat jest zgodny, formułuje się następujące hipotezy:
-H.lub: zmienna X ma rozkład prawdopodobieństwa f (x) z określonymi parametrami y1, Ydwa…, Yp
-H.1: X ma inny rozkład prawdopodobieństwa.
Rozkład prawdopodobieństwa przyjęty w hipotezie zerowej może być na przykład znanym rozkładem normalnym, a parametrami byłyby średnia μ i odchylenie standardowe σ.
Ponadto hipoteza zerowa jest oceniana z pewnym poziomem istotności, czyli miarą błędu, który zostałby popełniony w przypadku odrzucenia jej jako prawdziwej.
Zwykle ten poziom jest ustawiony na 1%, 5% lub 10%, a im niższy, tym bardziej wiarygodny jest wynik testu..
A jeśli zastosuje się test kontyngencji chi-kwadrat, który, jak powiedzieliśmy, służy do weryfikacji niezależności między dwiema zmiennymi X i Y, to hipotezy są następujące:
-H.lub: zmienne X i Y są niezależne.
-H.1: X i Y są zależne.
Ponownie konieczne jest określenie poziomu istotności, aby znać miarę błędu przy podejmowaniu decyzji..
Statystyka chi-kwadrat jest obliczana w następujący sposób:
Sumowanie odbywa się od pierwszej klasy i = 1 do ostatniej, czyli i = k.
Co więcej:
-falub to obserwowana częstotliwość (pochodzi z uzyskanych danych).
-fai to oczekiwana lub teoretyczna częstotliwość (należy obliczyć na podstawie danych).
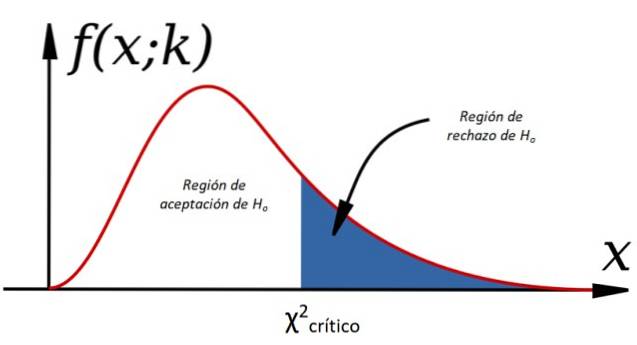
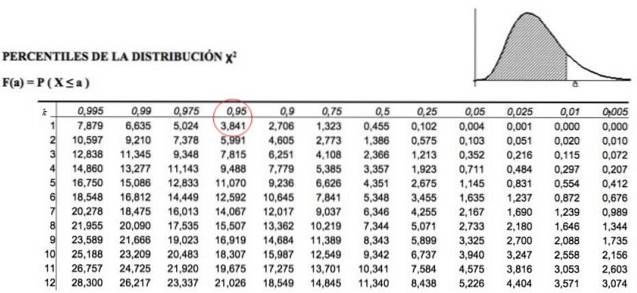
Aby zaakceptować lub odrzucić hipotezę zerową, obliczamy χdwa dla zaobserwowanych danych i porównane z wartością o nazwie krytyczny kwadrat chi, co zależy od stopni swobody k i poziom istotności α:
χdwakrytyczny = χdwak, α
Jeśli np. Chcemy przeprowadzić test z poziomem istotności 1%, to α = 0,01, jeśli będzie z 5%, to α = 0,05 i tak dalej. Definiujemy p, parametr rozkładu, jako:
p = 1 - α
Te krytyczne wartości chi-kwadrat są określane przez tabele zawierające skumulowaną wartość powierzchni. Na przykład dla k = 1, co oznacza 1 stopień swobody i α = 0,05, co równa się p = 1- 0,05 = 0,95, wartość χdwa wynosi 3841.
Kryterium przyjęcia H.lub to jest:
-Tak χdwa < χdwakrytyczny H jest akceptowanelub, w przeciwnym razie jest odrzucany (patrz rysunek 1).
W poniższej aplikacji test chi-kwadrat zostanie użyty jako test niezależności.
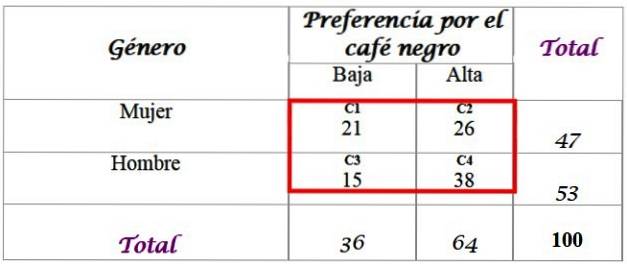
Załóżmy, że badacze chcą wiedzieć, czy preferencja dla czarnej kawy jest związana z płcią osoby i określają odpowiedź na poziomie istotności α = 0,05.
W tym celu dostępna jest próbka 100 osób, z którymi przeprowadzono wywiady, i ich odpowiedzi:
Ustal hipotezy:
-H.lub: płeć i preferencje dla czarnej kawy są niezależne.
-H.1: smak czarnej kawy jest powiązany z płcią osoby.
Oblicz oczekiwane częstości dla rozkładu, dla którego wymagane są sumy dodane w ostatnim wierszu iw prawej kolumnie tabeli. Każda komórka w czerwonym polu ma oczekiwaną wartość fai, która jest obliczana przez pomnożenie sumy z wiersza F przez sumę z kolumny C, podzieloną przez sumę próbki N:
fai = (F x C) / N
Wyniki są następujące dla każdej komórki:
-C1: (36 x 47) / 100 = 16,92
-C2: (64 x 47) / 100 = 30,08
-C3: (36 x 53) / 100 = 19,08
-C4: (64 x 53) / 100 = 33,92
Następnie dla tego rozkładu należy obliczyć statystykę chi-kwadrat według podanego wzoru:
Określ χdwakrytyczny, wiedząc, że zapisane dane znajdują się w f = 2 rzędach ic = 2 kolumnach, dlatego liczba stopni swobody wynosi:
k = (2-1) ⋅ (2-1) = 1.
Co oznacza, że w powyższej tabeli musimy poszukać wartości χdwak, α = χdwa1; 0,05 , który jest:
χdwakrytyczny = 3,841
Porównaj wartości i zdecyduj:
χdwa = 2,9005
χdwakrytyczny = 3,841
Od χdwa < χdwakrytyczny hipoteza zerowa zostaje przyjęta i stwierdza się, że preferencja dla czarnej kawy nie jest związana z płcią osoby, przy poziomie istotności 5%.



Jeszcze bez komentarzy