
Plik współczynnik determinacji to liczba z przedziału od 0 do 1, która reprezentuje ułamek punktów (X, Y), które następują po linii regresji dopasowania zestawu danych z dwiema zmiennymi.
Jest również znany jako Dobroć dopasowania i jest oznaczony przez Rdwa. Aby to obliczyć, przyjmuje się iloraz wariancji danych Ŷi oszacowanych przez model regresji i wariancji danych Yi odpowiadających każdemu Xi danych.
Rdwa = Sŷ / Sy

Jeśli 100% danych znajduje się na linii funkcji regresji, wówczas współczynnik determinacji będzie wynosił 1.
Wręcz przeciwnie, jeśli dla zbioru danych i określonej funkcji dostosowawczej współczynnik Rdwa okazuje się być równe 0,5, wówczas można powiedzieć, że dopasowanie jest w 50% zadowalające lub dobre.
Podobnie, gdy model regresji zwraca wartości R.dwa niższa niż 0,5 oznacza to, że wybrana funkcja dopasowania nie dostosowuje się w sposób zadowalający do danych, dlatego konieczne jest poszukanie innej funkcji dopasowania.
A kiedy kowariancja albo Współczynnik korelacji dąży do zera, wtedy zmienne X i Y w danych nie są ze sobą powiązane, a zatem Rdwa będzie również dążyć do zera.
Indeks artykułów
W poprzednim rozdziale powiedziano, że współczynnik determinacji oblicza się, znajdując iloraz wariancji:
-Oszacowane przez funkcję regresji zmiennej Y
-Zmienna Yi odpowiadająca każdej zmiennej Xi z N par danych.
Pod względem matematycznym wygląda to tak:
Rdwa = Sŷ / Sy
Z tego wzoru wynika, że R.dwa reprezentuje proporcję wariancji wyjaśnioną przez model regresji. Alternatywnie można obliczyć Rdwa używając następującego wzoru, całkowicie równoważnego z poprzednim:
Rdwa = 1 - (Sε / Sy)
Gdzie Sε reprezentuje wariancję reszt εi = Ŷi - Yi, podczas gdy Sy to wariancja zbioru wartości Yi danych. Do określenia Ŷi stosuje się funkcję regresji, co oznacza stwierdzenie, że Ŷi = f (Xi).
Wariancja zbioru danych Yi, gdzie i od 1 do N jest obliczana w następujący sposób:
Sy = [Σ (Yi -
Następnie postępuj w podobny sposób dla Sŷ lub Sε.
Aby pokazać szczegóły, w jaki sposób oblicza się współczynnik determinacji weźmiemy następujący zestaw czterech par danych:
(X, Y): (1, 1); (2. 3); (3, 6) i (4, 7).
Dla tego zbioru danych proponuje się dopasowanie regresji liniowej, które uzyskuje się metodą najmniejszych kwadratów:
f (x) = 2,1 x - 1
Stosując tę funkcję regulacji, uzyskuje się momenty:
(X, Ŷ): (1, 1.1); (2, 3,2); (3, 5,3) i (4, 7,4).
Następnie obliczamy średnią arytmetyczną dla X i Y:
Variance Sy
Sy = [(1 - 4,25)dwa + (3 - 4,25)dwa + (6 - 4,25)dwa +….…. (7 - 4,25)dwa] / (4-1) =
= [(-3,25)dwa+ (-1,25)dwa + (1,75)dwa + (2,75)dwa) / (3)] = 7,583
Wariancja Sŷ
Sŷ = [(1,1 - 4,25)dwa + (3,2 - 4,25)dwa + (5,3 - 4,25)dwa +….…. (7,4 - 4,25)dwa] / (4-1) =
= [(-3,25)dwa + (-1,25)dwa + (1,75)dwa + (2,75)dwa) / (3)] = 7,35
Współczynnik determinacji R.dwa
Rdwa = Sŷ / Sy = 7,35 / 7,58 = 0,97
Współczynnik determinacji dla przypadku poglądowego rozpatrywanego w poprzednim segmencie wyniósł 0,98. Innymi słowy, liniowa regulacja poprzez funkcję:
f (x) = 2,1x - 1
Jest w 98% wiarygodna w wyjaśnianiu danych, z którymi została uzyskana metodą najmniejszych kwadratów..
Oprócz współczynnika determinacji istnieje współczynnik korelacji liniowej lub znany również jako współczynnik Pearsona. Ten współczynnik, oznaczony jako r, oblicza się za pomocą następującej zależności:
r = Sxy / (Sx Sy)
Tutaj licznik reprezentuje kowariancję między zmiennymi X i Y, podczas gdy mianownik jest iloczynem odchylenia standardowego dla zmiennej X i odchylenia standardowego dla zmiennej Y.
Współczynnik Pearsona może przyjmować wartości od -1 do +1. Gdy współczynnik ten dąży do +1, istnieje bezpośrednia korelacja liniowa między X i Y. Jeśli zamiast tego zmierza do -1, występuje korelacja liniowa, ale gdy X rośnie, Y maleje. Wreszcie, jest blisko 0, nie ma korelacji między dwiema zmiennymi.
Należy zauważyć, że współczynnik determinacji pokrywa się z kwadratem współczynnika Pearsona tylko wtedy, gdy pierwszy został obliczony na podstawie dopasowania liniowego, ale ta równość nie dotyczy innych kształtek nieliniowych..
Grupa licealistów postanowiła wyznaczyć empiryczne prawo dotyczące okresu wahadła w funkcji jego długości. Aby osiągnąć ten cel, wykonują serię pomiarów, w których mierzą czas drgań wahadła dla różnych długości, uzyskując następujące wartości:
| Długość (m) | Okres (y) |
|---|---|
| 0,1 | 0.6 |
| 0,4 | 1.31 |
| 0,7 | 1.78 |
| 1 | 1,93 |
| 1.3 | 2.19 |
| 1.6 | 2,66 |
| 1.9 | 2.77 |
| 3 | 3.62 |
Wymagane jest sporządzenie wykresu punktowego danych i dopasowanie liniowe poprzez regresję. Pokaż również równanie regresji i jego współczynnik determinacji.
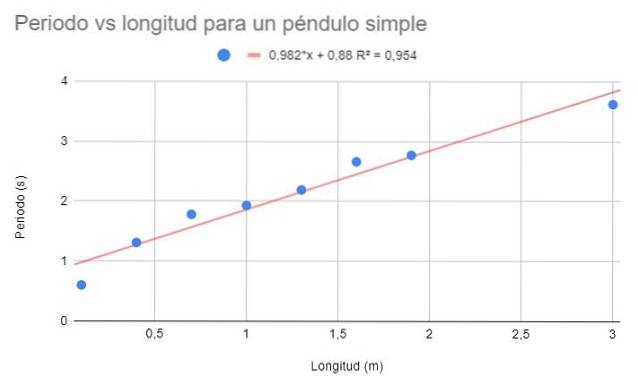
Można zaobserwować dość wysoki współczynnik determinacji (95%), więc można by sądzić, że dopasowanie liniowe jest optymalne. Jeśli jednak punkty są oglądane razem, wydaje się, że mają one tendencję do zakrzywiania się w dół. Ten szczegół nie jest uwzględniony w modelu liniowym.
Dla tych samych danych w przykładzie 1 wykonaj wykres punktowy danych. W tym przypadku, w przeciwieństwie do przykładu 1, żąda się korekty regresji przy użyciu funkcji potencjału.
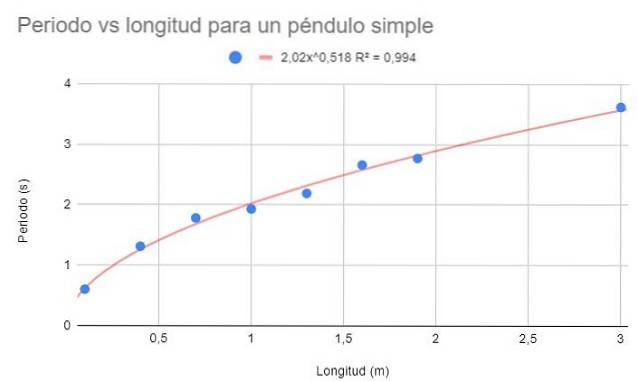
Pokaż także funkcję dopasowania i jej współczynnik determinacji Rdwa.
Funkcja potencjału ma postać f (x) = Axb, gdzie A i B są stałymi określanymi metodą najmniejszych kwadratów.
Na poprzednim rysunku przedstawiono funkcję potencjału i jej parametry, a także współczynnik determinacji o bardzo wysokiej wartości 99%. Zwróć uwagę, że dane są zgodne z krzywizną linii trendu.
Korzystając z tych samych danych z przykładu 1 i przykładu 2, przeprowadź dopasowanie wielomianu drugiego stopnia. Pokaż wykres, wielomian dopasowania i współczynnik determinacji Rdwa korespondent.
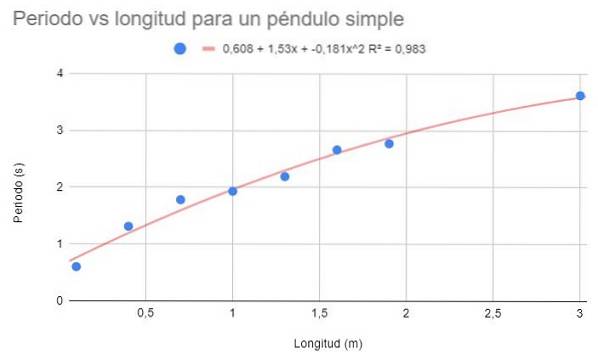
Przy dopasowaniu wielomianu drugiego stopnia można zobaczyć linię trendu, która dobrze pasuje do krzywizny danych. Ponadto współczynnik determinacji jest powyżej dopasowania liniowego i poniżej dopasowania potencjału..
Spośród trzech pokazanych pasowań, ten o najwyższym współczynniku determinacji jest dopasowaniem potencjału (przykład 2).
Potencjalne dopasowanie pokrywa się z fizyczną teorią wahadła, która, jak wiadomo, zakłada, że okres wahadła jest proporcjonalny do pierwiastka kwadratowego jego długości, przy czym stała proporcjonalności wynosi 2π / √g, gdzie g jest przyspieszeniem powaga.
Ten typ potencjalnego dopasowania ma nie tylko najwyższy współczynnik determinacji, ale wykładnik i stała proporcjonalności pasują do modelu fizycznego..
-Dopasowanie regresji określa parametry funkcji, której celem jest wyjaśnienie danych metodą najmniejszych kwadratów. Metoda ta polega na minimalizacji sumy kwadratów różnicy między wartością Y korekty a wartością Yi danych dla wartości Xi danych. Określa parametry funkcji regulacji.
-Jak widzieliśmy, najczęstszą funkcją dostosowującą jest linia, ale nie jedyna, ponieważ korekty mogą być również wielomianowe, potencjalne, wykładnicze, logarytmiczne i inne..
-W każdym przypadku współczynnik determinacji zależy od danych i typu dopasowania i jest wskaźnikiem jakości zastosowanego dopasowania..
-Wreszcie współczynnik determinacji wskazuje procent całkowitej zmienności między wartością Y danych względem wartości Ŷ dopasowania dla danego X.



Jeszcze bez komentarzy