Plik błąd próbkowania lub przykładowy błąd W statystyce jest to różnica między średnią wartością próby a średnią wartością całej populacji. Aby zilustrować tę ideę, wyobraźmy sobie, że całkowita populacja miasta to milion osób, z czego pożądany jest średni rozmiar buta, dla którego pobierana jest losowa próba tysiąca osób.
Średnia wielkość, która wyłania się z próby, niekoniecznie będzie pokrywać się z wielkością całej populacji, chociaż jeśli próbka nie jest obciążona, wartość musi być zbliżona. Ta różnica między średnią wartością próby a wartością całej populacji jest błędem próby.
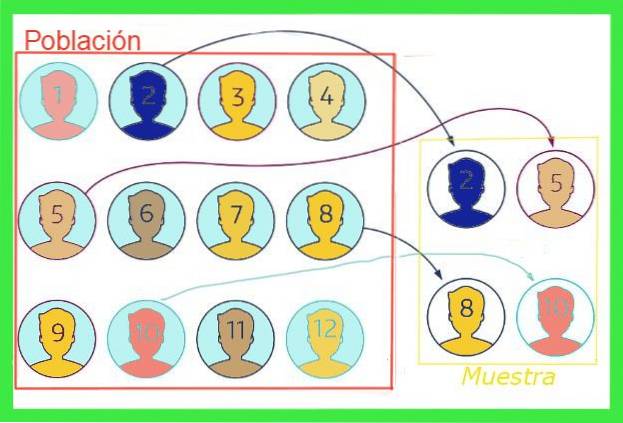
Ogólnie rzecz biorąc, średnia wartość całej populacji jest nieznana, ale istnieją techniki zmniejszania tego błędu i wzory do szacowania margines błędu próby które zostaną ujawnione w tym artykule.
Indeks artykułów
Powiedzmy, że chcesz poznać średnią wartość pewnej mierzalnej cechy x w populacji o wielkości N, ale jak N jest dużą liczbą, nie jest możliwe przeprowadzenie badania na całej populacji, a następnie przystępujemy do wykonania badania próbka losowa wielkościowy n<
Średnia wartość próbki jest oznaczona przez
Przypuśćmy, że biorą m próbki z całej populacji N, wszystkie tego samego rozmiaru n ze średnimi wartościami
Te średnie wartości nie będą identyczne i wszystkie będą zbliżone do średniej wartości populacji μ. Plik margines błędu próby E. wskazuje oczekiwane oddzielenie średnich wartości
Plik standardowy margines błędu ε wielkość próbki n to jest:
ε = σ / √n
gdzie σ to odchylenie standardowe (pierwiastek kwadratowy z wariancji), który jest obliczany według następującego wzoru:
σ = √ [(x -
Znaczenie standardowy margines błędu ε jest następujący:
Plik średnia wartość
W poprzedniej sekcji podano wzór do znalezienia zakres błędu standard próby o rozmiarze n, gdzie słowo standard wskazuje, że jest to margines błędu z 68% pewnością.
Oznacza to, że jeśli pobrano wiele próbek o tej samej wielkości n, 68% z nich poda wartości średnie
Istnieje prosta zasada zwana zasada 68-95-99.7 co pozwala nam znaleźć margines błąd próbkowania E. dla poziomów ufności wynoszących 68%, 95% Y 99,7% łatwo, ponieważ ten margines wynosi 1⋅ε, 2⋅ε i 3⋅ε odpowiednio.
Jeśli on poziom ufności γ nie jest żadnym z powyższych, to błąd próbkowania jest odchyleniem standardowym σ pomnożona przez współczynnik Zγ, który uzyskuje się za pomocą następującej procedury:
1. - Najpierw poziom istotności α który jest obliczany z poziom ufności γ za pomocą następującej relacji: α = 1 - γ
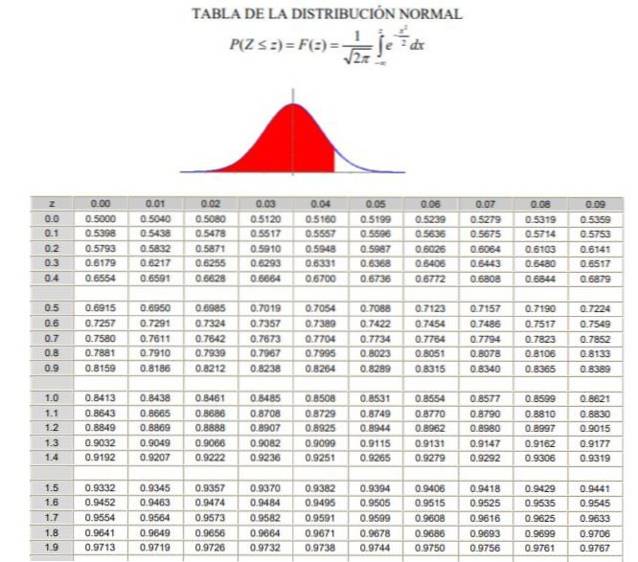
2. - Następnie musisz obliczyć wartość 1 - α / 2 = (1 + γ) / 2, co odpowiada skumulowanej częstotliwości normalnej między -∞ a Zγ, w normalnym lub znormalizowanym rozkładzie Gaussa F (z), którego definicję można zobaczyć na rysunku 2.
3. - Równanie zostało rozwiązane F (Zγ) = 1 - α / 2 za pomocą tabel rozkładu normalnego (skumulowanego) fa, lub za pomocą aplikacji komputerowej, która ma odwrotną znormalizowaną funkcję Gaussa fa-1.
W tym drugim przypadku mamy:
Zγ = G.-1(1 - α / 2).
4.- Wreszcie, ten wzór jest stosowany do błędu próbkowania z poziomem wiarygodności γ:
E = Zγ⋅(σ / √n)
Oblicz standardowy margines błędu w średniej wadze próbki 100 noworodków. Obliczenie średniej wagi było
Plik standardowy margines błędu to jest ε = σ / √n = (1500 kg) / √100 = 0,15 kg. Co oznacza, że na podstawie tych danych można wywnioskować, że waga 68% noworodków wynosi od 2950 kg do 3,25 kg..
Określać margines błędu próby E. oraz zakres masy ciała 100 noworodków z 95% poziomem ufności, jeśli średnia waga wynosi 3100 kg z odchyleniem standardowym σ = 1500 kg.
Jeśli zasada 68; 95; 99,7 → 1⋅ε; 2⋅ε; 3⋅ε, ty masz:
E = 2⋅ε = 2⋅0,15 kg = 0,30 kg
Oznacza to, że 95% noworodków będzie miało masę od 2800 kg do 3400 kg.
Określić zakres wagi noworodków z przykładu 1 z marginesem ufności 99,7%.
Błąd próbkowania z 99,7% pewnością wynosi 3 σ / √n, co dla naszego przykładu to E = 3 * 0,15 kg = 0,45 kg. Na tej podstawie wywnioskowano, że 99,7% noworodków będzie miało masę od 2650 kg do 3550 kg.
Określ współczynnik Zγ przy poziomie niezawodności 75%. Określić margines błędu próbkowania przy tym poziomie wiarygodności dla przypadku przedstawionego w przykładzie 1.
Plik poziom zaufania to jest γ = 75% = 0,75, co jest związane z poziom istotności α poprzez związek γ= (1 - α), tak aby poziom istotności był α = 1 - 0,75 = 0,25.
Oznacza to, że skumulowane normalne prawdopodobieństwo między -∞ a Zγ to jest:
P (Z ≤ Zγ ) = 1 - 0,125 = 0,875
Co odpowiada wartości Zγ 1.1503, jak pokazano na rysunku 3.
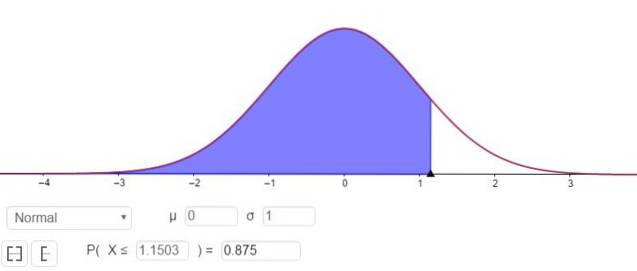
Oznacza to, że błąd próbkowania wynosi E = Zγ⋅(σ / √n)= 1.15⋅(σ / √n).
Po zastosowaniu do danych z przykładu 1 daje to błąd:
E = 1,15 * 0,15 kg = 0,17 kg
Z poziomem ufności 75%.
Jaki jest poziom ufności, jeśli Zα / 2 = 2,4 ?
P (Z ≤ Zα / 2 ) = 1 - α / 2
P (Z ≤ 2,4) = 1 - α / 2 = 0,9918 → α / 2 = 1 - 0,9918 = 0,0082 → α = 0,0164
Poziom istotności to:
α = 0,0164 = 1,64%
I wreszcie poziom zaufania pozostaje:
1- α = 1 - 0,0164 = 100% - 1,64% = 98,36%



Jeszcze bez komentarzy