Plik standardowy błąd szacunku mierzy odchylenie wartości próbki populacji. Oznacza to, że błąd standardowy oszacowania mierzy możliwe odchylenia średniej próby w odniesieniu do prawdziwej wartości średniej populacji..
Na przykład, jeśli chcesz poznać średni wiek populacji kraju (średnią populacji), bierzesz małą grupę mieszkańców, którą nazwiemy „próbą”. Z tego wyodrębnia się średni wiek (średnia z próby) i zakłada się, że populacja ma ten średni wiek ze standardowym błędem oszacowania, który różni się mniej więcej.
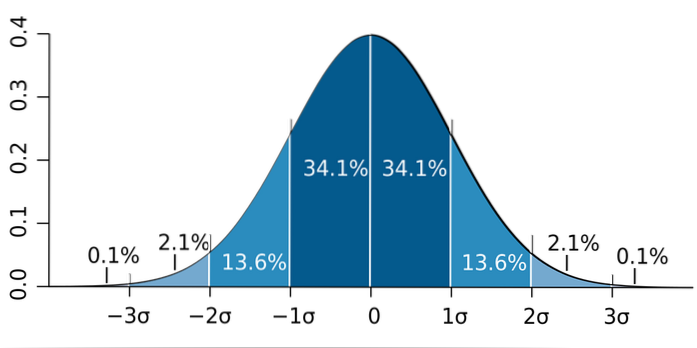
Należy zauważyć, że ważne jest, aby nie mylić odchylenia standardowego z błędem standardowym i błędem standardowym oszacowania:
1- Odchylenie standardowe jest miarą rozproszenia danych; to znaczy jest miarą zmienności populacji.
2- Błąd standardowy jest miarą zmienności próby, obliczoną na podstawie odchylenia standardowego populacji.
3- Błąd standardowy oszacowania jest miarą błędu, który popełnia się przy pobieraniu średniej z próby jako oszacowania średniej populacji.
Indeks artykułów
Błąd standardowy oszacowania można obliczyć dla wszystkich pomiarów uzyskanych w próbkach (na przykład błąd standardowy oszacowania średniej lub błędu standardowego oszacowania odchylenia standardowego) i mierzy błąd popełniony podczas szacowania prawdziwej populacji zmierzyć od wartości próbki
Ze standardowego błędu oszacowania konstruuje się przedział ufności odpowiedniej miary.
Ogólna struktura wzoru na błąd standardowy oszacowania jest następująca:
Błąd standardowy oszacowania = ± Współczynnik ufności * Błąd standardowy
Współczynnik ufności = wartość graniczna statystyki próby lub rozkładu próbkowania (m.in. normalny lub dzwon Gaussa, t-Studenta) dla danego przedziału prawdopodobieństwa.
Błąd standardowy = odchylenie standardowe populacji podzielone przez pierwiastek kwadratowy z wielkości próby.
Współczynnik ufności wskazuje liczbę błędów standardowych, które chcesz dodać i odjąć od miary, aby uzyskać określony poziom ufności wyników..
Załóżmy, że próbujesz oszacować odsetek osób w populacji, które mają zachowanie A i chcesz mieć 95% pewności co do swoich wyników..
Pobiera się próbkę n osób i określa proporcję próbki p i jej uzupełnienie q.
Błąd standardowy oszacowania (SEE) = ± Współczynnik ufności * Błąd standardowy
Współczynnik ufności = z = 1,96.
Błąd standardowy = pierwiastek kwadratowy ze stosunku między iloczynem udziału próbki i jej uzupełnieniem a wielkością próby n.
Na podstawie błędu standardowego oszacowania ustala się przedział, w którym oczekuje się znalezienia proporcji populacji lub proporcji innych próbek, które można utworzyć z tej populacji, z 95% poziomem ufności:
p - EEE ≤ Odsetek ludności ≤ p + EEE
1- Załóżmy, że próbujesz oszacować odsetek osób w populacji, które preferują mleko modyfikowane wzbogacone i chcesz mieć 95% pewności co do swoich wyników..
Pobiera się próbkę liczącą 800 osób, a 560 osób w próbce ma preferencje dla mleka modyfikowanego. Określić przedział, w którym można spodziewać się odsetka populacji i odsetka innych próbek, które można pobrać z populacji, z 95% pewnością
a) Obliczmy proporcję próbki p i jej uzupełnienie:
p = 560/800 = 0,70
q = 1 - p = 1 - 0,70 = 0,30
b) Wiadomo, że proporcja przybliża rozkład normalny do dużych próbek (powyżej 30). Następnie stosuje się tzw. Regułę 68 - 95 - 99.7 i musimy:
Współczynnik ufności = z = 1,96
Błąd standardowy = √ (p * q / n)
Błąd standardowy oszacowania (SEE) = ± (1,96) * √ (0,70) * (0,30) / 800) = ± 0,0318
c) Na podstawie błędu standardowego oszacowania ustala się przedział, w którym oczekuje się, że proporcja populacji zostanie znaleziona przy 95% poziomie ufności:
0,70 - 0,0318 ≤ Odsetek ludności ≤ 0,70 + 0,0318
0,6682 ≤ Odsetek ludności ≤ 0,7318
Można oczekiwać, że 70% odsetek próbki zmieni się nawet o 3,18 punktu procentowego, jeśli weźmiesz inną próbę 800 osób lub jeśli rzeczywisty odsetek populacji wynosi od 70 do 3,18 = 66,82% do 70 + 3,18 = 73,18%.
2- Weźmy z Spiegel i Stephens, 2008, następujące studium przypadku:
Z sumy ocen z matematyki studentów pierwszego roku uczelni pobrano losową próbę 50 stopni, z których uzyskano średnią 75 punktów i odchylenie standardowe 10 punktów. Jakie są 95-procentowe przedziały ufności dotyczące szacowania średnich ocen z matematyki w college'u??
a) Obliczmy standardowy błąd oszacowania:
95% współczynnik ufności = z = 1,96
Błąd standardowy = s / √n
Błąd standardowy oszacowania (SEE) = ± (1,96) * (10√50) = ± 2,7718
b) Na podstawie błędu standardowego oszacowania ustala się przedział, w którym oczekuje się znalezienia średniej populacji lub średniej innej próby o rozmiarze 50 z 95% poziomem ufności:
50 - 2,7718 ≤ Średnia populacji ≤ 50 + 2,7718
47,2282 ≤ Średnia populacji ≤ 52,7718
c) Można oczekiwać, że średnia z próby zmieni się aż o 2,7718 punktów, jeśli zostanie wybrana inna próba 50 stopni lub jeśli rzeczywista średnia ocen z matematyki z populacji uniwersytetu wynosi od 47,2282 punktów do 52,7718 punktów.



Jeszcze bez komentarzy