Plik losowe pobieranie próbek jest to sposób na wybranie statystycznie reprezentatywnej próby z danej populacji. Część zasady, że każdy element w próbie powinien mieć takie samo prawdopodobieństwo wyboru.
Losowanie jest przykładem losowania losowego, w którym każdemu członkowi populacji uczestnika przypisuje się numer. Aby wybrać liczby odpowiadające nagrodom w loterii (próbce), stosuje się jakąś przypadkową technikę, na przykład wyodrębnienie ze skrzynki pocztowej numerów zapisanych na identycznych kartach.
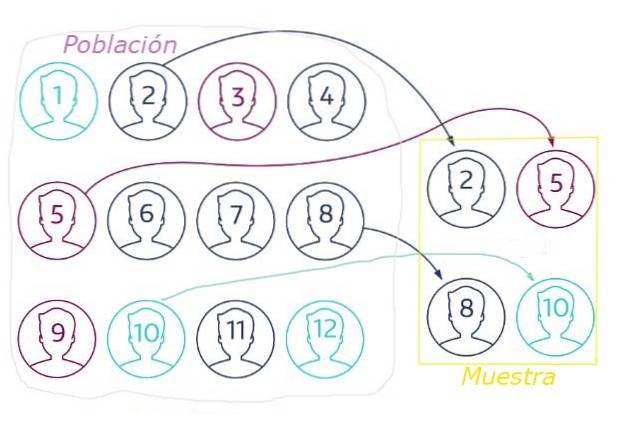
W losowym doborze próby istotny jest właściwy dobór wielkości próby, ponieważ niereprezentatywna próba populacji może prowadzić do błędnych wniosków ze względu na wahania statystyczne..
Indeks artykułów
Istnieją wzory na określenie właściwej wielkości próbki. Najważniejszym czynnikiem do rozważenia jest to, czy znana jest wielkość populacji. Przyjrzyjmy się formułom określającym wielkość próbki:
Gdy wielkość populacji N jest nieznana, można wybrać próbkę o odpowiedniej wielkości n, aby określić, czy dana hipoteza jest prawdziwa, czy fałszywa.
W tym celu stosuje się następujący wzór:
n = (Zdwa p q) / (E.dwa)
Gdzie:
-p to prawdopodobieństwo, że hipoteza jest prawdziwa.
-q jest prawdopodobieństwem, że tak nie jest, dlatego q = 1 - p.
-E to względny margines błędu, na przykład błąd 5% ma margines E = 0,05.
-Z ma związek z poziomem ufności wymaganym przez badanie.
W znormalizowanym (lub znormalizowanym) rozkładzie normalnym poziom ufności 90% ma Z = 1,645, ponieważ prawdopodobieństwo, że wynik mieści się w zakresie od -1,645σ do + 1,645σ, wynosi 90%, gdzie σ jest odchyleniem standardowym.
1. - 50% poziom ufności odpowiada Z = 0,675.
2. - poziom ufności 68,3% odpowiada Z = 1.
3.- 90% poziom ufności odpowiada Z = 1,645.
Poziom ufności 4 - 95% odpowiada Z = 1,96
Poziom ufności 5–95,5% odpowiada Z = 2.
6. - 99,7% poziom ufności odpowiada Z = 3.
Przykładem zastosowania tego wzoru byłoby badanie mające na celu określenie średniej masy kamyków na plaży.
Oczywiście nie jest możliwe zbadanie i zważenie wszystkich kamyków na plaży, dlatego zaleca się pobranie próbki tak losowej, jak to możliwe, z odpowiednią liczbą pierwiastków..

Gdy znana jest liczba N pierwiastków, które tworzą pewną populację (lub wszechświat), jeśli chcesz wybrać statystycznie istotną próbkę o rozmiarze n za pomocą prostego losowego próbkowania, oto wzór:
n = (Zdwap q N) / (N Edwa + Zdwap q)
Gdzie:
-Z jest współczynnikiem związanym z poziomem ufności.
-p to prawdopodobieństwo sukcesu hipotezy.
-q jest prawdopodobieństwem niepowodzenia hipotezy, p + q = 1.
-N to wielkość całej populacji.
-E jest względnym błędem wyniku badania.
Metodologia pobierania próbek zależy w dużej mierze od rodzaju badania, które należy wykonać. Dlatego losowe pobieranie próbek ma nieskończoną liczbę zastosowań:
Na przykład w ankietach telefonicznych osoby, które mają zostać skonsultowane, są wybierane za pomocą generatora liczb losowych, obowiązującego w badanym regionie..
Jeśli chcesz zastosować ankietę do pracowników dużej firmy, możesz skorzystać z selekcji respondentów poprzez numer pracownika lub numer dowodu osobistego.
Liczbę tę należy również wybrać losowo, korzystając np. Z generatora liczb losowych.

W przypadku, gdy badanie dotyczy części wytwarzanych przez maszynę, części należy wybierać losowo, ale z partii produkowanych o różnych porach dnia lub w różne dni lub tygodnie..
Proste losowe pobieranie próbek:
- Pozwala obniżyć koszty badania statystycznego, ponieważ nie jest konieczne badanie całej populacji, aby uzyskać statystycznie wiarygodne wyniki, przy pożądanych poziomach ufności i wymaganym w badaniu poziomie błędu..
- Unikaj stronniczości: ponieważ wybór badanych pierwiastków jest całkowicie przypadkowy, badanie wiernie odzwierciedla charakterystykę populacji, chociaż badano tylko część z nich.
- Ta metoda nie jest odpowiednia w przypadkach, gdy chcesz poznać preferencje w różnych grupach lub warstwach populacji.
W takim przypadku lepiej jest wcześniej określić grupy lub segmenty, na których ma być przeprowadzone badanie. Po zdefiniowaniu warstw lub grup, jeśli właściwe jest zastosowanie losowego pobierania próbek do każdej z nich..
- Uzyskanie informacji na temat sektorów mniejszościowych jest bardzo mało prawdopodobne, z których czasami konieczne jest poznanie ich cech.
Przykładowo, jeśli chodzi o przeprowadzenie kampanii na drogi produkt, to trzeba znać preferencje najzamożniejszych sektorów mniejszościowych.
Chcemy zbadać preferencje populacji dla określonego napoju typu cola, ale nie ma żadnego wcześniejszego badania w tej populacji, którego wielkość jest nieznana..
Z drugiej strony próba musi być reprezentatywna z minimalnym poziomem ufności 90%, a wnioski muszą mieć błąd procentowy 2%..
-Jak określić wielkość próby n?
-Jaka byłaby wielkość próby, gdyby margines błędu został zmniejszony do 5%??
Ponieważ liczebność populacji nie jest znana, do określenia liczebności próby stosuje się powyższy wzór:
n = (Zdwap q) / (E.dwa)
Zakładamy, że prawdopodobieństwo preferencji (p) dla naszej marki napoju bezalkoholowego jest takie samo jak brak preferencji (q), wtedy p = q = 0,5.
Z drugiej strony, jak wynik badania musi mieć błąd procentowy mniejszy niż 2%, to błąd względny E wyniesie 0,02.
Wreszcie wartość Z = 1,645 daje poziom ufności 90%.
Podsumowując, mamy następujące wartości:
Z = 1,645
p = 0,5
q = 0,5
E = 0,02
Na podstawie tych danych obliczana jest minimalna wielkość próby:
n = (1,645dwa 0,5 0,5) / (0,02dwa) = 1691,3
Oznacza to, że badanie z wymaganym marginesem błędu i przy wybranym poziomie ufności musi obejmować próbę co najmniej 1692 osób, wybranych w drodze losowania prostego..
Jeśli przejdziesz od marginesu błędu 2% do 5%, to nowy rozmiar próbki będzie następujący:
n = (1,645dwa 0,5 0,5) / (0,05dwa) = 271
Co oznacza znacznie mniejszą liczbę osobników. Podsumowując, wielkość próby jest bardzo wrażliwa na pożądany margines błędu w badaniu..



Jeszcze bez komentarzy