Plik prawdopodobieństwo częstotliwości wynosi subdefinicja w ramach badania prawdopodobieństwa i jego zjawisk. Jego metoda badania zdarzeń i atrybutów opiera się na dużej liczbie iteracji, obserwując w ten sposób trend każdego z nich w długim okresie lub nawet przy nieskończonej liczbie powtórzeń..
Na przykład koperta z żelek zawiera 5 gumek w każdym kolorze: niebieskim, czerwonym, zielonym i żółtym. Chcemy określić prawdopodobieństwo, że każdy kolor musi wyjść po losowym wyborze.

Trudno sobie wyobrazić, jak wyjąć gumę, zarejestrować ją, zwrócić, wyjąć gumkę i powtórzyć to samo kilkaset lub kilka tysięcy razy. Możesz nawet chcieć obserwować zachowanie po kilku milionach iteracji.
Wręcz przeciwnie, interesujące jest odkrycie, że po kilku powtórzeniach oczekiwane prawdopodobieństwo 25% nie jest w pełni spełnione, a przynajmniej nie dla wszystkich kolorów po wystąpieniu 100 iteracji..
Przy podejściu do prawdopodobieństwa częstotliwości, przypisanie wartości będzie dokonywane tylko poprzez badanie wielu iteracji. W ten sposób proces musi być przeprowadzony i zarejestrowany, najlepiej w sposób skomputeryzowany lub emulowany.
Wiele prądów odrzuca prawdopodobieństwo częstotliwości, argumentując brak empiryzmu i wiarygodności kryteriów losowości.
Indeks artykułów
Programując eksperyment w dowolnym interfejsie, który może zaoferować czysto losową iterację, można rozpocząć badanie prawdopodobieństwa częstotliwości zjawiska przy użyciu tabeli wartości.
Poprzedni przykład można zobaczyć z podejścia częstotliwościowego:
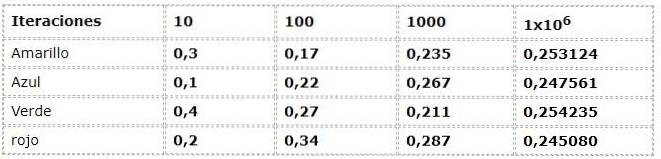
Dane liczbowe odpowiadają wyrażeniu:
N (a) = liczba wystąpień / liczba iteracji
Gdzie N (a) oznacza względną częstotliwość zdarzenia „a”
„A” należy do zbioru możliwych wyników lub przestrzeni próbkowania Ω
Ω: czerwony, zielony, niebieski, żółty
Doceniane jest duże rozrzuty w pierwszych iteracjach, obserwując częstości z różnicami nawet do 30% między nimi, co jest bardzo dużą liczbą danych dla eksperymentu, który teoretycznie ma zdarzenia z taką samą możliwością (Equiprobable).
Ale wraz ze wzrostem iteracji wartości wydają się coraz bardziej dostosowywać do przedstawionych przez teoretyczny i logiczny nurt..
Jako nieoczekiwana zgodność między podejściem teoretycznym a podejściem częstotliwościowym pojawia się prawo wielkich liczb. Tam, gdzie ustalono, że po znacznej liczbie iteracji wartości eksperymentu częstotliwości zbliżają się do wartości teoretycznych.
W przykładzie można zobaczyć, jak wartości zbliżają się do 0,250 w miarę wzrostu iteracji. Zjawisko to jest elementarne we wnioskach wielu prac probabilistycznych.

Istnieją 2 inne teorie lub podejścia do pojęcia prawdopodobieństwa oprócz prawdopodobieństwo częstotliwości.
Jego podejście jest zorientowane na dedukcyjną logikę zjawisk. W poprzednim przykładzie prawdopodobieństwo uzyskania każdego koloru w sposób zamknięty wynosi 25%. Oznacza to, że ich definicje i aksjomaty nie uwzględniają opóźnień poza ich zakresem danych probabilistycznych..
Opiera się na wiedzy i wcześniejszych przekonaniach, które każda osoba ma na temat zjawisk i atrybutów. Stwierdzenia, takie jak „W Wielkanoc zawsze pada ” Wynika to ze schematu podobnych wydarzeń, które miały miejsce wcześniej.
Początki jego realizacji sięgają XIX wieku, kiedy to Venn cytował go w kilku swoich pracach w Cambridge w Anglii. Jednak dopiero w XX wieku dwóch matematyków statystycznych opracowało i ukształtowało platformę prawdopodobieństwo częstotliwości.
Jednym z nich był Hans Reichenbach, który rozwija swoją pracę w takich publikacjach jak „Teoria prawdopodobieństwa” opublikowana w 1949 roku..
Drugim był Richard Von Mises, który dalej rozwijał swoją pracę poprzez liczne publikacje i proponował rozważenie prawdopodobieństwa jako nauki matematycznej. Koncepcja ta była nowa w matematyce i zapoczątkowała erę rozwoju nauk matematycznych. prawdopodobieństwo częstotliwości.
Właściwie to wydarzenie stanowi jedyną różnicę w wkładzie wniesionym przez pokolenie Venn, Cournot i Helm. Gdzie prawdopodobieństwo staje się homologiczne z naukami ścisłymi, takimi jak geometria i mechanika.
< La teoría de las probabilidades trata con masowe zjawiska i powtarzające się zdarzenia. Problemy, w których albo to samo zdarzenie jest powtarzane w kółko, albo w tym samym czasie występuje duża liczba jednolitych elementów> Richard Von Mises
Można sklasyfikować trzy typy:
W teorii, osoba dokonująca pomiaru odgrywa rolę w danych probabilistycznych, ponieważ to jej wiedza i doświadczenie wyrażają tę wartość lub prognozę..
w prawdopodobieństwo częstotliwości zdarzenia będą traktowane jako zbiory, które mają być traktowane, w przypadku gdy osoba fizyczna nie odgrywa żadnej roli w oszacowaniu.
W każdym elemencie występuje atrybut, który będzie zmienny zgodnie ze swoim charakterem. Na przykład w rodzaju zjawiska fizycznego cząsteczki wody będą miały różne prędkości..
W rzucie kośćmi znamy przestrzeń próbkowania Ω, która reprezentuje atrybuty eksperymentu.
Ω: 1, 2, 3, 4, 5, 6
Istnieją inne cechy, takie jak bycie równym ΩP. lub być dziwnym Ωja
Ωp : 2, 4, 6
Ωja : 1, 3, 5
Które można zdefiniować jako atrybuty nieelementowe.
W tym celu programuje się eksperyment, w którym w każdej iteracji dodawane są dwa źródła losowych wartości między [1, 6].
Dane są zapisywane w tabeli i badane są trendy w dużych ilościach.
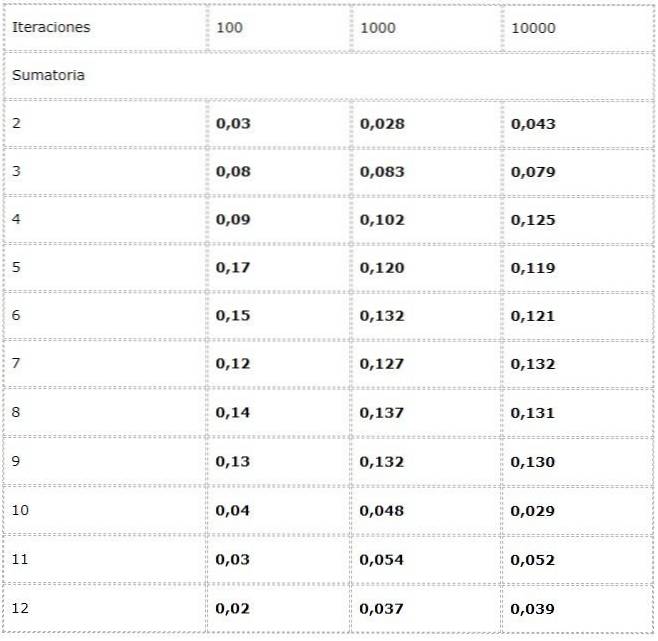
Zaobserwowano, że wyniki mogą się znacznie różnić między iteracjami. Jednak prawo wielkich liczb można zobaczyć w pozornej zbieżności przedstawionej w dwóch ostatnich kolumnach.


Jeszcze bez komentarzy