Plik stopnie swobody w statystyce są to liczba niezależnych składowych wektora losowego. Jeśli wektor ma n komponenty i są p równania liniowe, które odnoszą się do ich składników, a następnie stopień wolności jest n-p.
Pojęcie stopnie swobody Pojawia się również w mechanice teoretycznej, gdzie z grubsza odpowiada rozmiarowi przestrzeni, w której porusza się cząstka, pomniejszonym o liczbę wiązań..
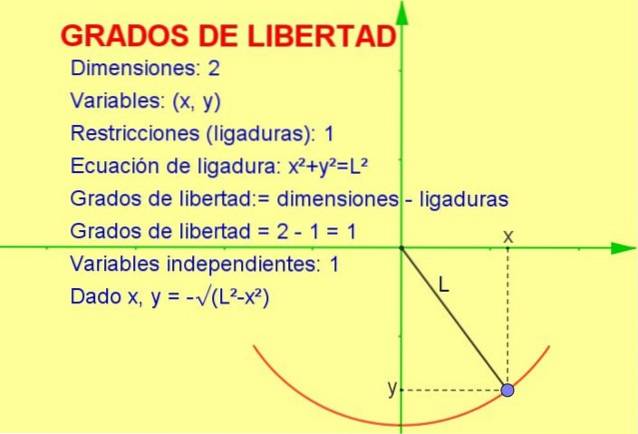
W tym artykule omówimy pojęcie stopni swobody stosowane w statystyce, ale przykład mechaniczny jest łatwiejszy do wizualizacji w postaci geometrycznej.
Indeks artykułów
W zależności od kontekstu, w jakim jest stosowany, sposób obliczania liczby stopni swobody może się różnić, ale podstawowa idea jest zawsze taka sama: wymiary całkowite minus liczba ograniczeń.
Rozważmy oscylującą cząstkę przywiązaną do struny (wahadła), która porusza się w pionowej płaszczyźnie x-y (2 wymiary). Jednak cząstka jest zmuszona do poruszania się po obwodzie o promieniu równym długości cięciwy.
Ponieważ cząstka może poruszać się tylko po tej krzywej, liczba stopnie swobody jest 1. Można to zobaczyć na rysunku 1.
Aby obliczyć liczbę stopni swobody, należy wziąć różnicę między liczbą wymiarów a liczbą wiązań:
stopnie swobody: = 2 (wymiary) - 1 (ligatura) = 1
Inne wyjaśnienie, które pozwala nam dojść do wyniku, jest następujące:
-Wiemy, że położenie w dwóch wymiarach jest reprezentowane przez punkt o współrzędnych (x, y).
-Ale ponieważ punkt musi spełniać równanie obwodu (xdwa + Ydwa = Ldwa) dla danej wartości zmiennej x, zmienna y jest określona przez wspomniane równanie lub ograniczenie.
Zatem tylko jedna ze zmiennych jest niezależna i system ma jeden (1) stopień swobody.
Aby zilustrować znaczenie tego pojęcia, załóżmy, że mamy wektor
x = (x1, xdwa,..., xn)
Co reprezentuje próbkę n wartości losowe o rozkładzie normalnym. W tym przypadku losowy wektor x mieć n niezależne komponenty i dlatego tak się mówi x mieć n stopni swobody.
Teraz zbudujmy wektor r na straty
r = (x1 -
Gdzie
A więc suma
(x1 -
Jest to równanie, które reprezentuje ograniczenie (lub wiązanie) na elementach wektora r reszt, ponieważ jeśli znane są n-1 składników wektora r, równanie wiązania określa nieznany komponent.
Dlatego wektor r o wymiarze n z ograniczeniem:
∑ (xja -
Mieć (n - 1) stopnie swobody.
Ponownie stosuje się, że obliczenie liczby stopni swobody wygląda następująco:
stopnie swobody: = n (wymiary) - 1 (więzy) = n-1
Wariancja sdwa definiuje się jako średnią kwadratu odchyleń (lub reszt) próbki n danych:
sdwa = (r•r) / (n-1)
gdzie r jest wektorem reszt r = (x1 -
sdwa = ∑ (xja -
W każdym razie należy zauważyć, że obliczając średnią kwadratu reszt, dzieli się ją przez (n-1), a nie przez n, ponieważ jak omówiono w poprzednim rozdziale, liczba stopni swobody wektor r jest (n-1).
Jeśli do obliczenia wariancji podzielono przez n zamiast (n-1) wynik miałby odchylenie, które jest bardzo istotne dla wartości n poniżej 50.
W literaturze formuła wariancji pojawia się również z dzielnikiem n zamiast (n-1), jeśli chodzi o wariancję populacji.
Ale zbiór zmiennej losowej reszt, reprezentowanych przez wektor r, Chociaż ma wymiar n, ma tylko (n-1) stopnie swobody. Jeśli jednak liczba danych jest wystarczająco duża (n> 500), obie formuły są zbieżne z tym samym wynikiem.
Kalkulatory i arkusze kalkulacyjne podają obie wersje wariancji i odchylenia standardowego (które jest pierwiastkiem kwadratowym z wariancji).
W związku z przedstawioną tutaj analizą, naszym zaleceniem jest, aby zawsze wybierać wersję z wartością (n-1) za każdym razem, gdy wymagane jest obliczenie wariancji lub odchylenia standardowego, aby uniknąć tendencyjnych wyników..
Niektóre rozkłady prawdopodobieństwa w ciągłej zmiennej losowej zależą od parametru o nazwie stopień wolności, jest przypadkiem rozkładu Chi-kwadrat (χdwa).
Nazwa tego parametru pochodzi właśnie od stopni swobody bazowego wektora losowego, do którego odnosi się ten rozkład.
Załóżmy, że mamy g populacji, z których pobrano próbki o rozmiarze n:
X1 = (x11, x1dwa,… X1n)
X2 = (x21, x2dwa,… X2n)
... .
Xjot = (xj1, xjdwa,… Xjn)
... .
Xg = (xg1, xgdwa,… Xgn)
Populacja jot co ma średnią
Zmienna standaryzowana lub znormalizowana zjja jest zdefiniowany jako:
zjja = (xjja -
I wektor Zj jest zdefiniowany w następujący sposób:
Zj = (zj1, zjdwa,..., zjja,..., zjn) i jest zgodny ze znormalizowanym rozkładem normalnym N (0,1).
Więc zmienna:
Q = ((z11 ^ 2 + z21^ 2 +…. + zg1^ 2),…., (Z1n^ 2 + z2n^ 2 +…. + zgn^ 2))
postępuj zgodnie z rozkładem χdwa(g) o nazwie rozkład chi-kwadrat ze stopniem swobody sol.
Jeśli chcesz przetestować hipotezy na podstawie określonego zestawu losowych danych, musisz znać liczba stopni swobody g aby móc zastosować test Chi-kwadrat.
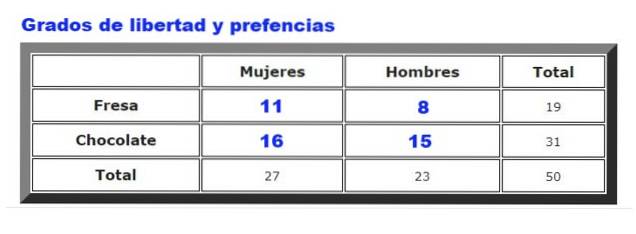
Jako przykład przeanalizowane zostaną dane zebrane na temat preferencji lodów czekoladowych lub truskawkowych wśród mężczyzn i kobiet w danej lodziarni. Częstotliwość, z jaką mężczyźni i kobiety wybierają truskawkę lub czekoladę, podsumowano na rycinie 2.
Najpierw obliczana jest tabela przewidywanych częstotliwości, którą przygotowuje się poprzez pomnożenie wartości suma wierszy dla niego suma kolumn, podzielony przez dane ogółem. Wynik przedstawiono na poniższym rysunku:

Następnie przystępujemy do obliczenia Chi-kwadrat (z danych) za pomocą następującego wzoru:
χdwa = ∑ (Flub - fai)dwa / Fi
Gdzie F.lub są obserwowanymi częstotliwościami (ryc. 2) i F.i są oczekiwanymi częstotliwościami (rysunek 3). Sumowanie obejmuje wszystkie wiersze i kolumny, które w naszym przykładzie dają cztery wyrazy.
Po wykonaniu operacji otrzymasz:
χdwa = 0,2043.
Teraz należy porównać z teoretycznym Chi-kwadrat, który zależy od liczba stopni swobody g.
W naszym przypadku ta liczba jest określana w następujący sposób:
g = (# wiersze - 1) (# kolumny - 1) = (2 - 1) (2 - 1) = 1 * 1 = 1.
Okazuje się, że liczba stopni swobody g w tym przykładzie wynosi 1.
Jeśli chcesz sprawdzić lub odrzucić hipotezę zerową (H0: nie ma korelacji między SMAK i PŁEĆ) przy poziomie istotności 1%, teoretyczną wartość Chi-kwadrat oblicza się ze stopniem swobody g = 1.
Poszukiwana jest wartość, która sprawia, że skumulowana częstotliwość (1 - 0,01) = 0,99, czyli 99%. Ta wartość (którą można odczytać z tabel) to 6,636.
Ponieważ teoretyczne Chi przewyższa obliczone, weryfikowana jest hipoteza zerowa.
To znaczy z zebranymi danymi, Nie zaobserwowany związek między zmiennymi SMAK i PŁEĆ.



Jeszcze bez komentarzy