Plik homoskedastyczność w predykcyjnym modelu statystycznym występuje, gdy we wszystkich grupach danych jednej lub więcej obserwacji wariancja modelu w odniesieniu do zmiennych objaśniających (lub niezależnych) pozostaje stała.
Model regresji może być homoskedastyczny lub nie, w którym to przypadku mówimy heteroskedastyczność.
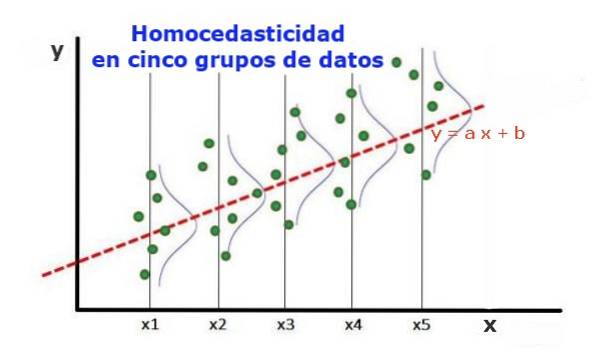
Statystyczny model regresji kilku zmiennych niezależnych nazywany jest homoskedastycznym tylko wtedy, gdy wariancja błędu zmiennej przewidywanej (lub odchylenia standardowego zmiennej zależnej) pozostaje jednolita dla różnych grup wartości zmiennych objaśniających lub niezależnych.
W pięciu grupach danych na ryc. 1 obliczono wariancję w każdej grupie w odniesieniu do wartości oszacowanej przez regresję, w wyniku czego była taka sama w każdej grupie. Zakłada się ponadto, że dane mają rozkład normalny.
Na poziomie graficznym oznacza to, że punkty są równo rozrzucone lub rozproszone wokół wartości przewidywanej przez dopasowanie regresji oraz że model regresji ma ten sam błąd i trafność dla zakresu zmiennej objaśniającej..
Indeks artykułów
Aby zilustrować znaczenie homoskedastyczności w statystyce predykcyjnej, konieczne jest przeciwstawienie się zjawisku przeciwstawnemu, heteroskedastyczności.
W przypadku rysunku 1, na którym występuje homoskedastyczność, prawdą jest, że:
Var ((y1-Y1); X1) ≈ Var ((y2-Y2); X2) ≈… Var ((y4-Y4); X4)
Gdzie Var ((yi-Yi); Xi) reprezentuje wariancję, para (xi, yi) reprezentuje dane z grupy i, podczas gdy Yi jest wartością przewidywaną przez regresję dla średniej wartości Xi grupy. Wariancję n danych z grupy i oblicza się w następujący sposób:
Var ((yi-Yi); Xi) = ∑j (yij - Yi) ^ 2 / n
Wręcz przeciwnie, w przypadku wystąpienia heteroskedastyczności model regresji może nie obowiązywać dla całego regionu, w którym został obliczony. Rysunek 2 przedstawia przykład takiej sytuacji.
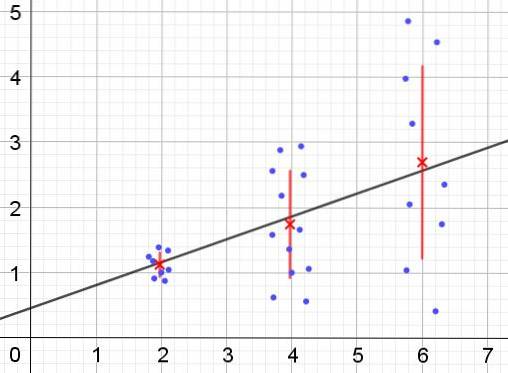
Rysunek 2 przedstawia trzy grupy danych i dopasowanie zestawu przy użyciu regresji liniowej. Należy zauważyć, że dane w drugiej i trzeciej grupie są bardziej rozproszone niż w pierwszej grupie. Wykres na rysunku 2 pokazuje również średnią wartość dla każdej grupy i jej słupek błędu ± σ, z odchyleniem standardowym σ dla każdej grupy danych. Należy pamiętać, że odchylenie standardowe σ jest pierwiastkiem kwadratowym z wariancji.
Wyraźnie widać, że w przypadku heteroskedastyczności błąd estymacji regresji zmienia się w zakresie wartości zmiennej objaśniającej lub niezależnej, aw przedziałach, w których ten błąd jest bardzo duży, predykcja regresji jest niewiarygodna lub nie ma zastosowania.
W modelu regresji błędy lub reszty (i -Y) muszą być rozłożone z równą wariancją (σ ^ 2) w przedziale wartości zmiennej niezależnej. Z tego powodu dobry model regresji (liniowy lub nieliniowy) musi przejść test homoskedastyczności..
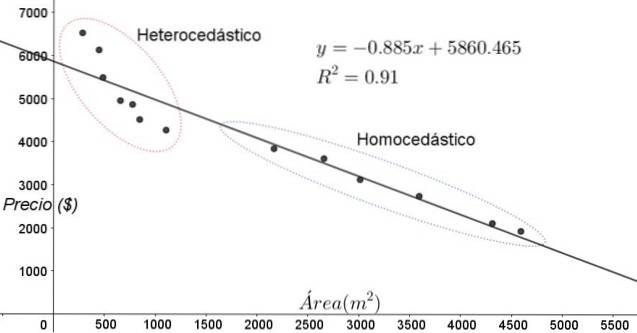
Punkty pokazane na rysunku 3 odpowiadają danym z badania, które szuka związku między cenami (w dolarach) domów w funkcji wielkości lub powierzchni w metrach kwadratowych.
Pierwszym testowanym modelem jest regresja liniowa. W pierwszej kolejności należy zauważyć, że współczynnik determinacji R ^ 2 dopasowania jest dość wysoki (91%), więc można uznać, że dopasowanie jest zadowalające..
Jednak na wykresie dostosowania można wyraźnie odróżnić dwa regiony. Jeden z nich, ten po prawej stronie zamknięty w owalu, spełnia homoskedastyczność, podczas gdy obszar po lewej stronie nie ma homoskedastyczności.
Oznacza to, że przewidywanie modelu regresji jest adekwatne i wiarygodne w zakresie od 1800 m ^ 2 do 4800 m ^ 2, ale bardzo nieadekwatne poza tym obszarem. W strefie heteroskedastycznej błąd jest nie tylko bardzo duży, ale także dane wydają się wykazywać inny trend niż ten, który proponuje model regresji liniowej..
Wykres punktowy danych jest najprostszym i najbardziej wizualnym testem ich homoskedastyczności, jednak w przypadkach, gdy nie jest to tak oczywiste, jak w przykładzie pokazanym na rysunku 3, konieczne jest odwołanie się do wykresów ze zmiennymi pomocniczymi..
W celu wyodrębnienia obszarów, w których homoskedastyczność jest spełniona, a gdzie jej nie ma, wprowadzono znormalizowane zmienne ZRes i ZPred:
ZRes = Abs (y - Y) / σ
ZPred = Y / σ
Należy zauważyć, że zmienne te zależą od zastosowanego modelu regresji, ponieważ Y jest wartością prognozy regresji. Poniżej znajduje się wykres punktowy ZRes vs ZPred dla tego samego przykładu:
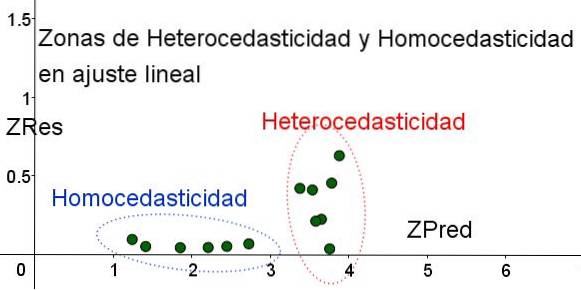
Na wykresie na rysunku 4 ze znormalizowanymi zmiennymi obszar, w którym błąd resztowy jest mały i jednolity, jest wyraźnie oddzielony od obszaru, w którym go nie ma. W pierwszej strefie zachodzi homoskedastyczność, natomiast w rejonie, w którym błąd szczątkowy jest bardzo zmienny i duży, spełniona jest heteroskedastyczność..
Korekta regresji jest stosowana do tej samej grupy danych na rysunku 3, w tym przypadku korekta jest nieliniowa, ponieważ zastosowany model obejmuje funkcję potencjalną. Wynik przedstawiono na poniższym rysunku:
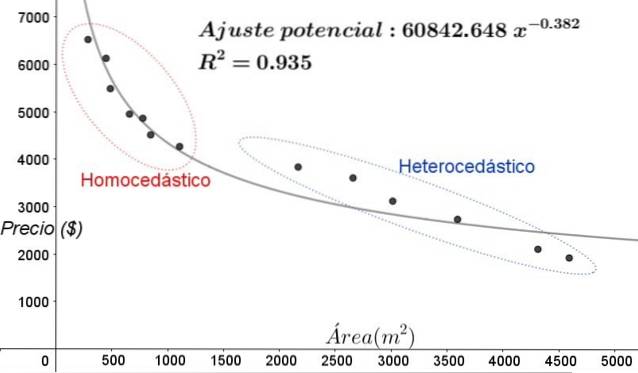
Na wykresie na rycinie 5 należy wyraźnie zaznaczyć strefy homoskedastyczne i heteroskedastyczne. Należy również zauważyć, że strefy te zostały zamienione w stosunku do tych, które zostały utworzone w modelu dopasowania liniowego.
Na wykresie z rysunku 5 widać, że nawet przy dość wysokim współczynniku determinacji dopasowania (93,5%) model nie jest adekwatny dla całego przedziału zmiennej objaśniającej, gdyż dane dla wartości większych niż 2000 m ^ 2 przedstawia heteroskedastyczność.
Jednym z testów niegraficznych najczęściej używanych do weryfikacji, czy homoskedastyczność jest spełniona, czy nie, jest Test Breuscha-Pagana.
Nie wszystkie szczegóły tego testu zostaną podane w tym artykule, ale jego podstawowe cechy i etapy tego testu są zarysowane szerokimi kreskami:
Większość pakietów oprogramowania statystycznego, takich jak: SPSS, MiniTab, R, Python Pandas, SAS, StatGraphic i kilka innych, zawiera test homoskedastyczności Breusch-Pagan. Kolejny test sprawdzający jednorodność wariancji Test Levene'a.


Jeszcze bez komentarzy