Plik ocena klasy, Znany również jako punkt środkowy, jest to wartość znajdująca się w środku klasy, która reprezentuje wszystkie wartości znajdujące się w tej kategorii. Zasadniczo znak klasy służy do obliczania pewnych parametrów, takich jak średnia arytmetyczna lub odchylenie standardowe..
Tak więc znacznik klasy jest środkiem dowolnego przedziału. Ta wartość jest również bardzo przydatna do znalezienia wariancji zestawu danych już pogrupowanych w klasy, co z kolei pozwala nam zrozumieć, jak daleko od centrum znajdują się te konkretne dane.

Indeks artykułów
Aby zrozumieć, czym jest znak klasy, konieczne jest pojęcie rozkładu częstotliwości. Biorąc pod uwagę zestaw danych, rozkład częstotliwości to tabela, która dzieli dane na kilka kategorii zwanych klasami..
Wspomniana tabela przedstawia liczbę elementów należących do każdej klasy; ta ostatnia jest znana jako częstotliwość.
W tej tabeli część informacji, które otrzymujemy z danych, jest poświęcona, ponieważ zamiast mieć indywidualną wartość każdego elementu, wiemy tylko, że należy on do tej klasy.
Z drugiej strony zyskujemy lepsze zrozumienie zbioru danych, gdyż w ten sposób łatwiej jest docenić ustalone wzorce, co ułatwia manipulowanie wspomnianymi danymi..
Aby dokonać rozkładu częstotliwości, musimy najpierw określić liczbę klas, które chcemy wziąć i wybrać ich granice klas..
Wybór liczby zajęć powinien być wygodny, biorąc pod uwagę, że niewielka liczba zajęć może skrywać informacje o danych, które chcemy zbadać, a bardzo duża może generować zbyt wiele szczegółów, które niekoniecznie są przydatne.
Czynniki, które musimy wziąć pod uwagę przy wyborze liczby klas do wzięcia, jest kilka, ale spośród tych dwóch wyróżniają się: pierwszy to uwzględnienie ilości danych, które musimy wziąć pod uwagę; druga to wiedzieć, jak duży jest zakres rozkładu (czyli różnica między największą i najmniejszą obserwacją).
Po zdefiniowaniu klas przystępujemy do liczenia, ile danych znajduje się w każdej klasie. Ta liczba nazywana jest częstotliwością zajęć i jest oznaczona przez fi.
Jak powiedzieliśmy wcześniej, mamy do czynienia z rozkładem częstotliwości, który traci informacje pochodzące z poszczególnych danych lub obserwacji. Z tego powodu poszukiwana jest wartość, która reprezentuje całą klasę, do której należy; ta wartość jest znakiem klasy.
Znak klasy jest podstawową wartością, którą reprezentuje klasa. Uzyskuje się ją poprzez dodanie granic przedziału i podzielenie tej wartości przez dwa. Możemy to matematycznie wyrazić w następujący sposób:
xja= (Dolna granica + Górna granica) / 2.
W tym wyrażeniu xja oznacza znak i-tej klasy.
Biorąc pod uwagę poniższy zestaw danych, podaj reprezentatywny rozkład częstotliwości i uzyskaj ocenę odpowiednich klas.

Ponieważ dane o najwyższej wartości liczbowej to 391, a najniższa to 221, mamy zakres 391-221 = 170.
Wybierzemy 5 klas, wszystkie w tym samym rozmiarze. Oto jeden ze sposobów wyboru zajęć:

Zwróć uwagę, że wszystkie dane są w klasie, są rozłączne i mają tę samą wartość. Innym sposobem wyboru klas jest rozważenie danych jako części zmiennej ciągłej, która może osiągnąć dowolną wartość rzeczywistą. W tym przypadku możemy rozważyć klasy postaci:
205-245, 245-285, 285-325, 325-365, 365-405
Jednak ten sposób grupowania danych może powodować pewne graniczne niejednoznaczności. Na przykład w przypadku 245 pojawia się pytanie: do której klasy należy, do pierwszej czy do drugiej?
Aby uniknąć tego zamieszania, stworzono konwencję dotyczącą punktów końcowych. W ten sposób pierwsza klasa będzie przedziałem (205,245], druga (245,285] itd..

Po zdefiniowaniu klas przystępujemy do obliczania częstotliwości i mamy następującą tabelę:
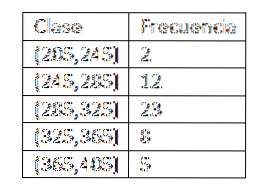
Po uzyskaniu rozkładu częstotliwości danych przystępujemy do wyszukiwania ocen klas dla każdego przedziału. W efekcie musimy:
x1= (205+ 245) / 2 = 225
xdwa= (245+ 285) / 2 = 265
x3= (285+ 325) / 2 = 305
x4= (325+ 365) / 2 = 345
x5= (365+ 405) / 2 = 385
Możemy to przedstawić na poniższym wykresie:
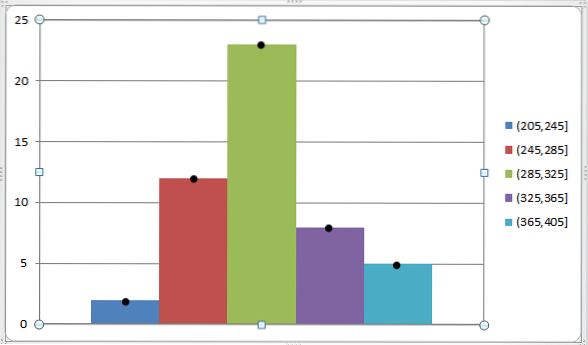
Jak wspomniano wcześniej, ocena klasy jest bardzo przydatna do znajdowania średniej arytmetycznej i wariancji grupy danych, które zostały już pogrupowane w różne klasy..
Średnią arytmetyczną możemy zdefiniować jako sumę obserwacji uzyskanych pomiędzy liczebnością próby. Z fizycznego punktu widzenia jego interpretacja przypomina punkt równowagi zbioru danych.
Identyfikacja całego zestawu danych za pomocą jednej liczby może być ryzykowna, dlatego należy również wziąć pod uwagę różnicę między tym progiem rentowności a rzeczywistymi danymi. Wartości te są znane jako odchylenie od średniej arytmetycznej i za ich pomocą staramy się określić, jak bardzo zmienia się średnia arytmetyczna danych..
Najczęstszym sposobem znalezienia tej wartości jest wariancja, która jest średnią kwadratów odchyleń od średniej arytmetycznej.
Aby obliczyć średnią arytmetyczną i wariancję zbioru danych zgrupowanych w klasach, używamy odpowiednio następujących formuł:
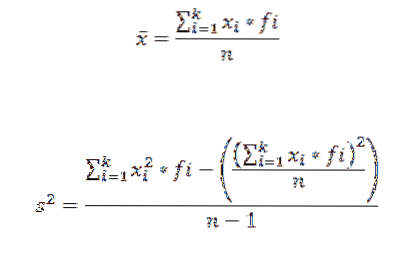
W tych wyrażeniach xja jest znakiem I-tej klasy, fja reprezentuje odpowiednią częstotliwość, ik liczbę klas, w których zgrupowano dane.
Korzystając z danych podanych w poprzednim przykładzie, możemy nieco bardziej rozszerzyć dane tabeli rozkładu częstotliwości. Otrzymujesz:
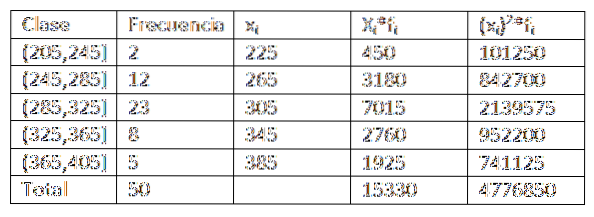
Następnie, podstawiając dane we wzorze, otrzymujemy średnią arytmetyczną:
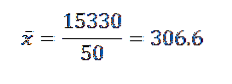
Jego wariancja i odchylenie standardowe to:
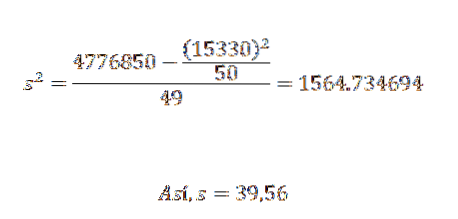
Z tego możemy wywnioskować, że oryginalne dane mają średnią arytmetyczną 306,6 i odchylenie standardowe 39,56..

Jeszcze bez komentarzy