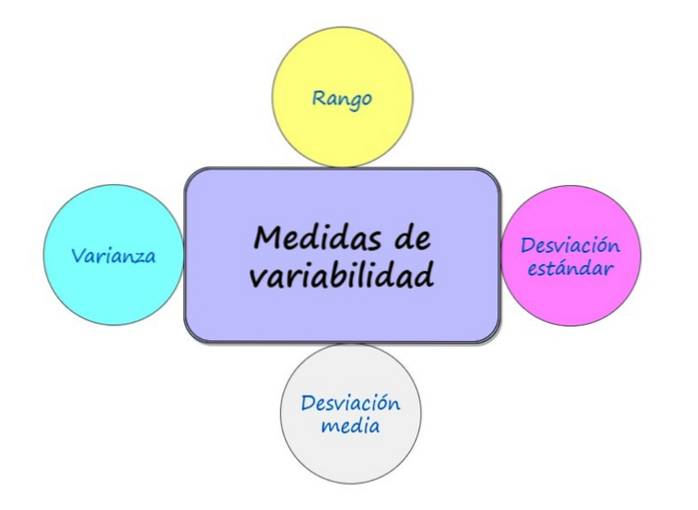
Plik miary zmienności, Nazywane również miarami dyspersji, są wskaźnikami statystycznymi, które wskazują, jak blisko lub daleko znajdują się dane od ich średniej arytmetycznej. Jeśli dane są bliskie średniej, rozkład jest skoncentrowany, a jeśli są daleko, jest to rozkład rzadki..
Istnieje wiele miar zmienności, a do najbardziej znanych należą:
Miary te uzupełniają miary o tendencji centralnej i są niezbędne do zrozumienia rozkładu uzyskanych danych i wydobycia z nich jak największej ilości informacji..
Zakres lub rozpiętość mierzy szerokość zbioru danych. Aby określić jego wartość, należy wziąć pod uwagę różnicę między danymi o najwyższej wartości xmax i ten o najniższej wartości xmin:
R = xmax - xmin
Jeśli dane nie są luźne, ale pogrupowane według przedziałów, wówczas zakres jest obliczany na podstawie różnicy między górną granicą ostatniego przedziału a dolną granicą pierwszego przedziału.
Kiedy zakres jest małą wartością, oznacza to, że wszystkie dane są dość blisko siebie, ale duży zakres wskazuje, że istnieje duża zmienność. Wyraźnie widać, że poza górną i dolną granicą danych zakres nie uwzględnia wartości między nimi, dlatego nie zaleca się stosowania go przy dużej ilości danych.
Jednak jest to miara natychmiastowa do obliczenia i ma te same jednostki danych, więc jest łatwa do zinterpretowania.
Poniżej znajduje się lista z liczbą bramek strzelonych w weekend w ligach piłkarskich dziewięciu krajów:
40, 32, 35, 36, 37, 31, 37, 29, 39
To jest niezgrupowany zestaw danych. Aby znaleźć zakres, uporządkujemy je od najniższego do najwyższego:
29, 31, 32, 35, 36, 37, 37, 39, 40
Dane o najwyższej wartości to 40 celów, a te o najniższej wartości to 29, dlatego zakres jest następujący:
R = 40−29 = 11 bramek.
Można uznać, że rozpiętość jest niewielka w porównaniu z wartością minimalną, która wynosi 29 bramek, więc można założyć, że dane nie charakteryzują się dużą zmiennością.
Ta miara zmienności jest obliczana jako średnia wartości bezwzględnych odchyleń w stosunku do średniej.. Oznaczając średnie odchylenie jako D.M, W przypadku danych niepogrupowanych średnie odchylenie oblicza się według następującego wzoru:
Gdzie n to liczba dostępnych danych, xja reprezentuje wszystkie dane, a x̄ jest średnią, która jest określana przez dodanie wszystkich danych i podzielenie przez n:
Odchylenie średnie pozwala wiedzieć, średnio w ilu jednostkach dane odbiegają od średniej arytmetycznej i ma tę zaletę, że mają te same jednostki, co dane, z którymi pracujemy.
Na podstawie danych z przykładu zakresu liczba strzelonych bramek wynosi:
40, 32, 35, 36, 37, 31, 37, 29, 39
Jeśli chcesz znaleźć średnie odchylenie DM Z tych danych należy najpierw obliczyć średnią arytmetyczną x̄:

A teraz, gdy znana jest wartość x̄, przystępujemy do wyznaczenia średniego odchylenia DM:
= 2,99 ≈ 3 bramki
W związku z tym można stwierdzić, że przeciętnie dane są oddalone o około 3 bramki od średniej, która wynosi 35 bramek i jak zauważono, jest to miara znacznie dokładniejsza niż przedział..
Odchylenie średnie jest znacznie dokładniejszą miarą zmienności niż przedział, ale ponieważ jest obliczane na podstawie wartości bezwzględnej różnic między poszczególnymi danymi a średnią, nie zapewnia większej wszechstronności z algebraicznego punktu widzenia..
Z tego powodu preferowana jest wariancja, która odpowiada średniej z kwadratowej różnicy poszczególnych danych ze średnią i jest obliczana według wzoru:
W tym wyrażeniu sdwa oznacza wariancję i jak zawsze xja reprezentuje każdą z danych, x̄ to średnia, an to suma danych.
Podczas pracy z próbą zamiast z populacją zaleca się obliczenie wariancji w następujący sposób:
W każdym razie wariancja charakteryzuje się tym, że zawsze jest wielkością dodatnią, ale ponieważ jest średnią z różnic kwadratowych, należy zauważyć, że nie ma tych samych jednostek, co dane..
Aby obliczyć wariancję danych w przykładach zakresu i odchylenia średniego, przystępujemy do podstawiania odpowiednich wartości i wykonujemy wskazane sumowanie. W tym przypadku wybieramy podzielenie przez n-1:

= 13,86
Wariancja nie ma tej samej jednostki, co zmienna badana, na przykład, jeśli dane są w metrach, wariancja jest wyrażona w metrach kwadratowych. Lub w przykładzie celów byłoby to w postaci kwadratów bramek, co nie ma sensu.
Dlatego definiuje się odchylenie standardowe, zwane również typowe odchylenie, jako pierwiastek kwadratowy z wariancji:
s = √sdwa
W ten sposób miara zmienności danych jest uzyskiwana w tych samych jednostkach, co te, a im niższa wartość s, tym bardziej pogrupowane są dane wokół średniej..
Zarówno wariancja, jak i odchylenie standardowe są miarami zmienności, które należy wybrać, gdy średnia arytmetyczna jest miarą tendencji centralnej, która najlepiej opisuje zachowanie danych..
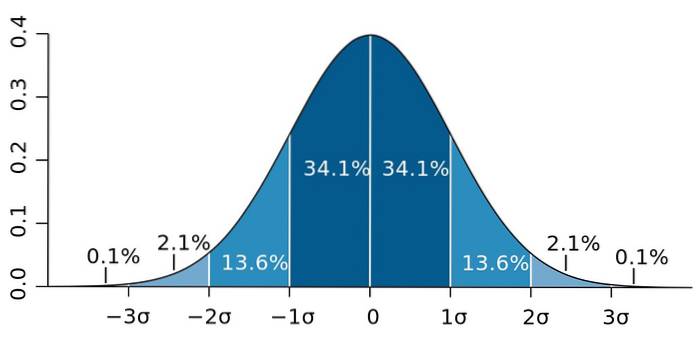
Chodzi o to, że odchylenie standardowe ma ważną właściwość, znaną jako twierdzenie Czebyszewa: co najmniej 75% obserwacji znajduje się w przedziale określonym przez x̄ ± 2 s. Innymi słowy, 75% danych jest oddalonych co najwyżej o 2 sekundy od średniej..
Podobnie co najmniej 89% wartości znajduje się w odległości 3 s od średniej, co jest wartością procentową, którą można rozszerzyć, o ile dostępnych jest dużo danych i mają one rozkład normalny..
Rysunek 2. - Jeśli dane mają rozkład normalny, 95,4 z nich mieści się w granicach dwóch odchyleń standardowych po obu stronach średniej. Źródło: Wikimedia Commons.
Odchylenie standardowe danych przedstawionych w poprzednich przykładach wynosi:
s = √sdwa = √13,86 = 3,7 ≈ 4 bramki

Jeszcze bez komentarzy