Plik trzecia postać normalna (bazy danych) jest techniką projektowania relacyjnej bazy danych, w której różne tabele, które ją tworzą, są nie tylko zgodne z drugą formą normalną, ale wszystkie ich atrybuty lub pola zależą bezpośrednio od klucza podstawowego.
Podczas projektowania bazy danych głównym celem jest stworzenie dokładnej reprezentacji danych, relacji między nimi oraz odpowiednich ograniczeń danych..
Aby osiągnąć ten cel, można zastosować pewne techniki projektowania baz danych, między innymi normalizację.
Jest to proces organizowania danych w bazie danych w celu uniknięcia nadmiarowości i ewentualnych anomalii przy wstawianiu, aktualizowaniu lub eliminowaniu danych, generując prosty i stabilny projekt modelu koncepcyjnego..
Rozpoczyna się od zbadania związku funkcjonalnego lub zależności między atrybutami. Opisują one pewne właściwości danych lub relacje między nimi.
Indeks artykułów
Normalizacja wykorzystuje serię testów, zwanych formami normalnymi, aby pomóc zidentyfikować optymalne grupowanie tych atrybutów i ostatecznie ustalić odpowiedni zestaw relacji, które obsługują wymagania firmy dotyczące danych.
Oznacza to, że technika normalizacji jest zbudowana wokół pojęcia postaci normalnej, która definiuje system ograniczeń. Jeśli relacja spełnia ograniczenia określonej postaci normalnej, mówi się, że relacja jest w tej postaci normalnej.
Mówi się, że tabela znajduje się w 1FN, jeśli wszystkie atrybuty lub pola w niej zawarte zawierają tylko unikalne wartości. Oznacza to, że każda wartość każdego atrybutu musi być niepodzielna.
Z definicji relacyjna baza danych będzie zawsze znormalizowana do pierwszej postaci normalnej, ponieważ wartości atrybutów są zawsze niepodzielne. Wszystkie relacje w bazie danych znajdują się w 1FN.
Jednak zwykłe opuszczenie bazy danych w ten sposób stymuluje szereg problemów, takich jak nadmiarowość i możliwe niepowodzenia aktualizacji. Aby rozwiązać te problemy, opracowano wyższe formy normalne..
Zajmuje się eliminacją zależności cyklicznych z tabeli. Mówi się, że relacja jest w 2FN, jeśli jest w 1FN, a także każde pole lub atrybut niebędący kluczem zależy całkowicie od klucza podstawowego, a dokładniej zapewnia, że tabela ma jeden cel.
Atrybut inny niż klucz to każdy atrybut, który nie jest częścią klucza podstawowego relacji.
Zajmuje się usuwaniem zależności przechodnich z tabeli. Oznacza to, że należy usunąć atrybuty niebędące kluczem, które nie zależą od klucza podstawowego, ale od innego atrybutu.
Zależność przechodnia to typ zależności funkcjonalnej, w której wartość atrybutu lub pola niebędącego kluczem jest określana przez wartość innego pola, które również nie jest kluczem..
Wyszukaj powtarzające się wartości w atrybutach niebędących kluczami, aby upewnić się, że te atrybuty niebędące kluczami nie zależą od niczego innego niż klucz podstawowy.
Mówi się, że atrybuty są wzajemnie niezależne, jeśli żaden z nich nie jest funkcjonalnie zależny od kombinacji innych. Ta wzajemna niezależność gwarantuje, że atrybuty mogą być aktualizowane indywidualnie, bez niebezpieczeństwa wpływania na inny atrybut..
Dlatego, aby relacja z bazą danych miała trzecią normalną postać, musi być zgodna z:
- Wszystkie wymagania 2FN.
- Jeśli istnieją atrybuty niezwiązane z kluczem podstawowym, należy je usunąć i umieścić w osobnej tabeli, wiążącej obie tabele za pomocą klucza obcego. Oznacza to, że nie powinno być żadnych zależności przechodnich.
Niech tabela będzie STUDENT, której klucz podstawowy to identyfikator studenta (STUDENT_ID) i składa się z następujących atrybutów: STUDENT_NAME, STREET, CITY i POST_CODE, spełniając warunki 2FN.
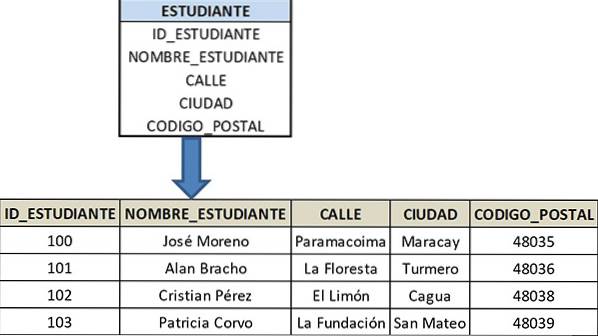
W tym przypadku ULICA i MIASTO nie mają bezpośredniego związku z kluczem podstawowym STUDENT_ID, ponieważ nie są bezpośrednio związane z uczniem, ale są całkowicie zależne od kodu pocztowego.
Ponieważ uczeń znajduje się w miejscu określonym przez CODE_POSTAL, STREET i CITY są powiązane z tym atrybutem. Ze względu na ten drugi stopień zależności nie jest konieczne przechowywanie tych atrybutów w tabeli STUDENT.
Załóżmy, że pod tym samym kodem pocztowym znajduje się wielu uczniów, a tabela STUDENT ma ogromną liczbę rekordów i wymagana jest zmiana nazwy ulicy lub miasta, wtedy tę ulicę lub miasto należy znaleźć i zaktualizować w cały stół. STUDENT.
Na przykład, jeśli konieczna jest zmiana ulicy „El Limón” na „El Limón II”, będziesz musiał wyszukać „El Limón” w całej tabeli STUDENT, a następnie zaktualizować ją do „El Limón II”.
Wyszukiwanie w ogromnej tabeli i aktualizowanie pojedynczego lub wielu rekordów zajmie dużo czasu, a tym samym wpłynie na wydajność bazy danych.
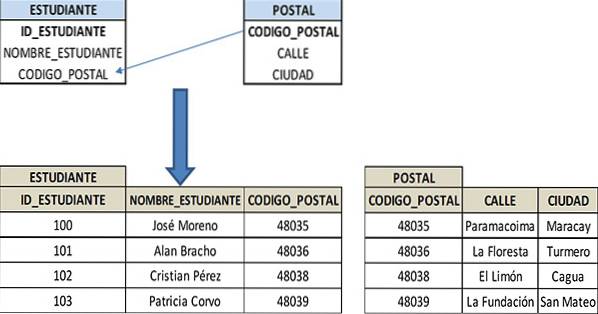
Zamiast tego dane te mogą być przechowywane w oddzielnej tabeli (POSTCARD), która jest powiązana z tabelą STUDENT za pomocą atrybutu POST_CODE.
Tabela POST będzie miała stosunkowo mniej rekordów, a ta tabela POST będzie musiała zostać zaktualizowana tylko raz. Zostanie to automatycznie odzwierciedlone w tabeli STUDENT, upraszczając bazę danych i zapytania. Stoły będą więc w 3FN:
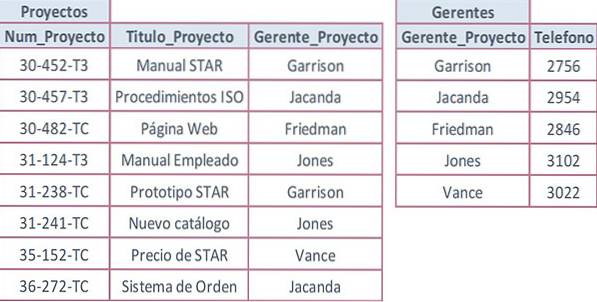
Niech poniższa tabela będzie używana z polem Project_Num jako kluczem podstawowym oraz z powtarzającymi się wartościami w atrybutach, które nie są kluczami.
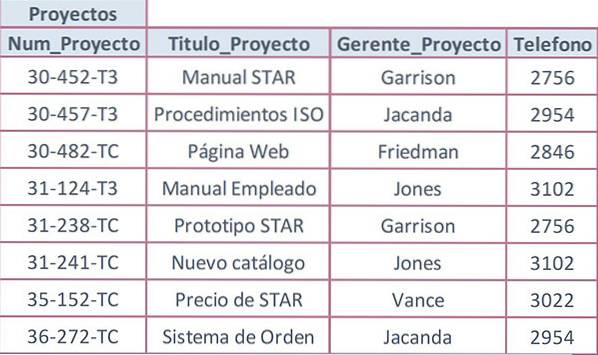
Wartość Telefon jest powtarzana za każdym razem, gdy powtarzane jest nazwisko menedżera. Dzieje się tak, ponieważ numer telefonu jest zależny tylko od numeru projektu. To naprawdę zależy najpierw od menedżera, a to z kolei zależy od numeru projektu, co powoduje zależność przechodnią.
Atrybut Project_Manager nie może być możliwym kluczem w tabeli Projekty, ponieważ ten sam menedżer zarządza więcej niż jednym projektem. Rozwiązaniem jest usunięcie atrybutu z powtarzającymi się danymi (Phone), tworząc oddzielną tabelę.
Odpowiednie atrybuty należy zgrupować razem, tworząc nową tabelę, aby je zapisać. Dane są wprowadzane i sprawdzane, czy powtarzane wartości nie są częścią klucza podstawowego. Klucz podstawowy jest ustawiany dla każdej tabeli, aw razie potrzeby dodawane są klucze obce.
Aby zachować zgodność z trzecią normalną formą, tworzona jest nowa tabela (Menedżerowie) w celu rozwiązania problemu. Obie tabele są powiązane przez pole Project_Manager:


Jeszcze bez komentarzy