Plik zgrupowane dane to te, które zostały podzielone na kategorie lub klasy, biorąc za kryterium ich częstotliwość. Odbywa się to w celu uproszczenia obsługi dużych ilości danych i ustalenia ich trendów..
Po uporządkowaniu w te klasy według ich częstotliwości dane tworzą plik rozkład częstotliwości, z którego pozyskuje się przydatne informacje poprzez jego cechy.

Oto prosty przykład zgrupowanych danych:
Załóżmy, że mierzony jest wzrost 100 studentek wybranych ze wszystkich podstawowych kierunków fizyki na uniwersytecie i uzyskuje się następujące wyniki:

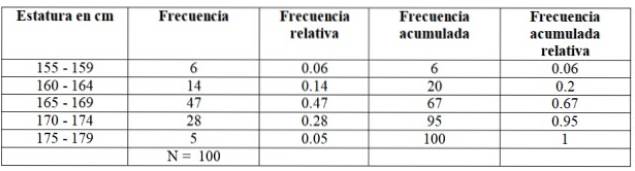
Uzyskane wyniki podzielono na 5 klas, które pojawiają się w lewej kolumnie.
W pierwszej klasie liczącej od 155 do 159 cm jest 6 uczniów, w drugiej klasie od 160 do 164 cm jest 14 uczniów, w trzeciej klasie od 165 do 169 cm jest najwięcej osób: 47. Następnie klasa trwa 170-174 cm. z 28 uczniami i wreszcie 175-174 cm z zaledwie 5.
Liczba członków każdej klasy jest dokładnie taka sama częstotliwość lub Absolutna frecuency a dodając je wszystkie, uzyskuje się łączne dane, które w tym przykładzie wynoszą 100.
Indeks artykułów
Jak widzieliśmy, częstotliwość to liczba powtórzeń danych. Aby ułatwić obliczenia właściwości rozkładu, takich jak średnia i wariancja, zdefiniowano następujące wielkości:
-Skumulowana częstotliwość: jest otrzymywany przez dodanie częstotliwości klasy z poprzednią zakumulowaną częstotliwością. Pierwsza ze wszystkich częstotliwości odpowiada częstotliwości z danego przedziału, a ostatnia to całkowita liczba danych.
-Względna częstotliwość: obliczone poprzez podzielenie bezwzględnej częstotliwości każdej klasy przez całkowitą liczbę danych. A jeśli pomnożymy przez 100, otrzymamy względną częstotliwość procentową.
-Skumulowana częstotliwość względna: jest sumą względnych częstości każdej klasy z nagromadzoną poprzednią. Ostatnia z zakumulowanych częstotliwości względnych musi być równa 1.
W naszym przykładzie częstotliwości wyglądają następująco:
Nazywa się skrajne wartości każdej klasy lub przedziału limity klasowe. Jak widać, każda klasa ma niższy i wyższy limit. Na przykład pierwsza klasa w badaniu wzrostu ma dolną granicę 155 cm i wyższą 159 cm..
Ten przykład ma jasno określone granice, jednak możliwe jest zdefiniowanie granic otwartych: jeśli zamiast definiować dokładne wartości, powiedzmy „wysokość mniejsza niż 160 cm”, „wysokość mniejsza niż 165 cm” i tak dalej.
Wysokość jest zmienną ciągłą, więc można uznać, że pierwsza klasa faktycznie zaczyna się od 154,5 cm, ponieważ zaokrąglenie tej wartości do najbliższej liczby całkowitej daje 155 cm.
Ta klasa obejmuje wszystkie wartości do 159,5 cm, ponieważ po tym wysokość jest zaokrąglana do 160,0 cm. Wzrost 159,7 cm należy już do następnej klasy.
Rzeczywiste granice klas w tym przykładzie są w cm:
Szerokość klasy uzyskuje się odejmując granice. Dla pierwszego przedziału naszego przykładu mamy 159,5 - 154,5 cm = 5 cm.
Czytelnik może zweryfikować, że dla pozostałych przedziałów przykładu amplituda również wynosi 5 cm. Należy jednak zauważyć, że rozkłady można konstruować z przedziałami o różnej amplitudzie.
Jest to punkt środkowy przedziału i jest uzyskiwany jako średnia między górną granicą a dolną granicą.
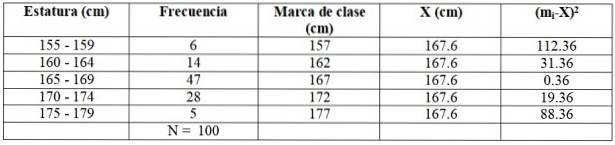
W naszym przykładzie pierwsza klasa to (155 + 159) / 2 = 157 cm. Czytelnik widzi, że pozostałe oceny klas to: 162, 167, 172 i 177 cm.
Określenie ocen klas jest ważne, ponieważ są one niezbędne do znalezienia średniej arytmetycznej i wariancji rozkładu.
Najczęściej stosowanymi miarami tendencji centralnej są średnia, mediana i mod i precyzyjnie opisują one tendencję danych do skupiania się wokół określonej wartości centralnej..
Jest to jeden z głównych mierników tendencji centralnej. W danych zgrupowanych średnią arytmetyczną można obliczyć ze wzoru:

-X jest średnią
-faja to częstotliwość zajęć
-mja to ocena klasy
-g to liczba klas
-n to całkowita liczba danych
W przypadku mediany konieczne jest określenie przedziału, w którym występuje obserwacja n / 2. W naszym przykładzie ta obserwacja ma numer 50, ponieważ w sumie jest 100 punktów danych. Ta obserwacja mieści się w przedziale 165-169 cm.
Następnie musisz dokonać interpolacji, aby znaleźć wartość liczbową, która odpowiada tej obserwacji, dla której używany jest wzór:
Gdzie:
-c = szerokość przedziału, w którym znajduje się mediana
-bM = dolna granica przedziału, do którego należy mediana
-fam = liczba obserwacji zawartych w medianie
-n / 2 = połowa wszystkich danych
-faBM = całkowita liczba obserwacji przed mediana przedziału
W przypadku trybu identyfikowana jest klasa modalna, zawierająca najwięcej obserwacji, której znak klasy jest znany.
Wariancja i odchylenie standardowe są miarami dyspersji. Jeśli oznaczymy wariancję przez sdwa a odchylenie standardowe, które jest pierwiastkiem kwadratowym z wariancji jako s, dla danych zgrupowanych otrzymamy odpowiednio:
Y
Dla zaproponowanego na wstępie rozkładu wzrostu studentek należy obliczyć wartości:
a) Średnia
b) Mediana
c) Moda
d) Wariancja i odchylenie standardowe.
Zbudujmy następującą tabelę, aby ułatwić obliczenia:

Podstawianie wartości i bezpośrednie przeprowadzanie sumowania:
X = (6 x 157 + 14 x 162 + 47 x 167 + 28 x 172+ 5 x 177) / 100 cm =
= 167,6 cm
Przedział, do którego należy mediana, wynosi 165-169 cm, ponieważ jest to przedział o największej częstotliwości.
Zidentyfikujmy każdą z tych wartości w przykładzie, korzystając z tabeli 2:
c = 5 cm (patrz sekcja dotycząca amplitudy)
bM = 164,5 cm
fam = 47
n / 2 = 100/2 = 50
faBM = 20
Podstawiając we wzorze:
Przedział, w którym znajduje się większość obserwacji, to 165-169 cm, którego ocena klasowa to 167 cm.
Rozszerzamy poprzednią tabelę, dodając dwie dodatkowe kolumny:
Stosujemy formułę:
I opracowujemy podsumowanie:
sdwa = (6 x 112,36 + 14 x 31,36 + 47 x 0,36 + 28 x 19,36 + 5 x 88,36) / 99 = = 21,35 cmdwa
W związku z tym:
s = √ 21,35 cmdwa = 4,6 cm



Jeszcze bez komentarzy