Plik niezgrupowane dane to te, które uzyskane na podstawie badania nie są jeszcze zorganizowane w ramach zajęć. Kiedy jest to możliwa do zarządzania liczba danych, zwykle 20 lub mniej, i jest niewiele różnych danych, można je traktować jako niepogrupowane i wartościowe informacje z nich wyodrębnione.
Dane niezgrupowane pochodzą z ankiety lub badania przeprowadzonego w celu ich uzyskania, a zatem nie są przetwarzane. Spójrzmy na kilka przykładów:

-Wyniki testu IQ na 20 przypadkowych studentach z uniwersytetu. Uzyskane dane były następujące:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112,106
-Wiek 20 pracowników pewnej popularnej kawiarni:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
-Średnia końcowa ocen 10 uczniów z matematyki:
3,2; 3.1; 2,4; 4,0; 3,5; 3.0; 3,5; 3,8; 4,2; 4.9
Indeks artykułów
Istnieją trzy ważne właściwości, które charakteryzują zbiór danych statystycznych, niezależnie od tego, czy są one zgrupowane, czy nie:
-Pozycja, czyli tendencja danych do skupiania się wokół pewnych wartości.
-Dyspersja, wskazanie, jak rozproszone lub rozproszone są dane wokół danej wartości.
-Kształt, Odnosi się do sposobu, w jaki dane są dystrybuowane, co jest doceniane, gdy konstruuje się taki sam wykres. Istnieją bardzo symetryczne krzywe, a także skośne, albo w lewo, albo w prawo od określonej wartości centralnej.
Dla każdej z tych właściwości istnieje szereg miar, które je opisują. Po uzyskaniu dostarczają nam przeglądu zachowania danych:
-Najczęściej używanymi miarami pozycji są średnia arytmetyczna lub po prostu średnia, mediana i tryb.
-Zakres, wariancja i odchylenie standardowe są często używane w dyspersji, ale nie są jedynymi miarami dyspersji..
-Aby określić kształt, średnia i mediana są porównywane poprzez odchylenie, co wkrótce zobaczysz.
-Średnia arytmetyczna, znany również jako średnia i oznaczony jako X, jest obliczany w następujący sposób:
X = (x1 + xdwa + x3 +… Xn) / n
Gdzie x1, xdwa,… xn, są danymi, a n jest ich sumą. W podsumowaniu mamy:
-Mediana to wartość, która pojawia się w środku uporządkowanej sekwencji danych, więc aby ją uzyskać, należy najpierw uporządkować dane.
Jeśli liczba obserwacji jest nieparzysta, nie ma problemu ze znalezieniem punktu środkowego zbioru, ale jeśli mamy parzystą liczbę danych, dwa centralne dane są przeszukiwane i uśredniane.
-Moda jest najczęstszą wartością obserwowaną w zbiorze danych. Nie zawsze istnieje, ponieważ jest możliwe, że żadna wartość nie jest powtarzana częściej niż inna. Mogą również istnieć dwie dane o równej częstotliwości, w którym to przypadku mówimy o rozkładzie bimodalnym.
W przeciwieństwie do poprzednich dwóch miar, tryb może być używany z danymi jakościowymi.
Zobaczmy, jak obliczane są te miary pozycji na przykładzie:
Załóżmy, że chcemy wyznaczyć średnią arytmetyczną, medianę i modę w przykładzie zaproponowanym na początku: wiek 20 pracowników stołówki:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
Plik pół oblicza się go po prostu przez dodanie wszystkich wartości i podzielenie przez n = 20, czyli całkowitą liczbę danych. W ten sposób:
X = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22,3 lat.
Aby znaleźć mediana musisz najpierw posortować zbiór danych:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Ponieważ jest to parzysta liczba danych, dwa główne dane, wyróżnione pogrubioną czcionką, są pobierane i uśredniane. Ponieważ oboje mają po 22 lata, mediana wynosi 22 lata.
Wreszcie moda Są to dane, które powtarzają się najczęściej lub takie, których częstotliwość jest większa, bo są to 22 lata.
Zakres jest po prostu różnicą między największą i najmniejszą z danych i pozwala szybko ocenić zmienność danych. Ale oprócz tego istnieją inne miary rozproszenia, które oferują więcej informacji na temat dystrybucji danych..
Wariancja jest oznaczana jako si jest obliczana za pomocą wyrażenia:
Aby poprawnie zinterpretować wyniki, odchylenie standardowe definiuje się jako pierwiastek kwadratowy z wariancji lub też quasi-odchylenie standardowe, które jest pierwiastkiem kwadratowym z quasi-wariancji:
Jest to porównanie między średnią X i medianą Med:
-Jeśli Med = średnia X: dane są symetryczne.
-Kiedy X> Med: pochyl w prawo.
-A jeśli X < Med: los datos sesgan hacia la izquierda.
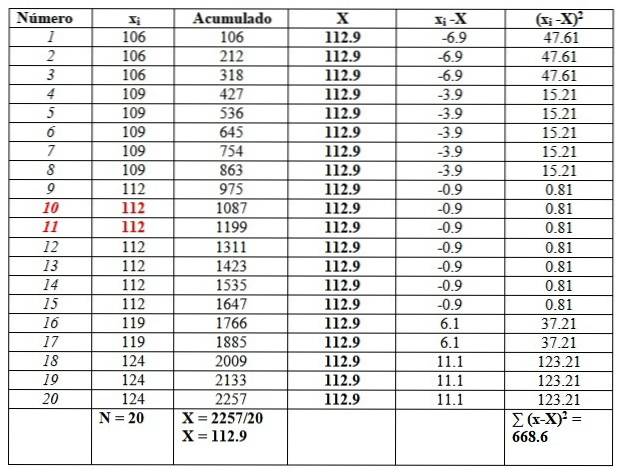
Znajdź średnią, medianę, modę, zakres, wariancję, odchylenie standardowe i odchylenie wyników testu IQ przeprowadzonego na 20 studentach z uniwersytetu:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
Zamówimy dane, ponieważ konieczne będzie znalezienie mediany.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
I umieścimy je w poniższej tabeli, aby ułatwić obliczenia. Druga kolumna zatytułowana „Skumulowane” to suma odpowiednich danych plus poprzednia..
Ta kolumna pomoże łatwo znaleźć średnią, dzieląc ostatnie zgromadzone przez całkowitą liczbę danych, jak widać na końcu kolumny „Skumulowane”:
X = 112,9
Mediana to średnia danych centralnych zaznaczonych na czerwono: liczba 10 i liczba 11. Ponieważ są one takie same, mediana wynosi 112.
Wreszcie tryb jest wartością, która jest najczęściej powtarzana i wynosi 112 z 7 powtórzeniami..
Jeśli chodzi o miary dyspersji, zakres wynosi:
124-106 = 18.
Wariancję uzyskuje się, dzieląc wynik końcowy w prawej kolumnie przez n:
s = 668,6 / 20 = 33,42
W tym przypadku odchylenie standardowe jest pierwiastkiem kwadratowym z wariancji: √33,42 = 5,8.
Z drugiej strony wartości quasi-wariancji i quasi-odchylenia standardowego to:
sdo= 668,6 / 19 = 35,2
Odchylenie quasi-standardowe = √35,2 = 5,9
Wreszcie odchylenie jest nieco w prawo, ponieważ średnia 112,9 jest większa niż mediana 112.



Jeszcze bez komentarzy