
Plik normalna dystrybucja lub rozkład Gaussa jest rozkładem prawdopodobieństwa w zmiennej ciągłej, w której funkcja gęstości prawdopodobieństwa jest opisana funkcją wykładniczą argumentu kwadratowego i ujemnego, co daje kształt dzwonu.
Nazwa rozkładu normalnego bierze się stąd, że rozkład ten dotyczy największej liczby sytuacji, w których w danej grupie lub populacji występuje jakaś ciągła zmienna losowa..
Przykłady zastosowania rozkładu normalnego to: wzrost mężczyzn lub kobiet, różnice w mierze wielkości fizycznej lub mierzalnych cech psychologicznych lub socjologicznych, takich jak iloraz intelektualny lub nawyki konsumpcyjne określonego produktu.
Z drugiej strony nazywa się to rozkładem Gaussa lub dzwonem Gaussa, ponieważ to ten niemiecki geniusz matematyczny przypisuje swoje odkrycie za zastosowanie, które podał do opisania błędu statystycznego pomiarów astronomicznych w roku 1800..
Jednak stwierdzono, że ten rozkład statystyczny został wcześniej opublikowany przez innego wielkiego matematyka francuskiego pochodzenia, takiego jak Abraham de Moivre, jeszcze w roku 1733.
Indeks artykułów
Do funkcji rozkładu normalnego w zmiennej ciągłej x, z parametrami μ Y σ jest oznaczony przez:
N (x; μ, σ)
i jest to wyraźnie napisane w ten sposób:
N (x; μ, σ) = ∫-∞x f (s; μ, σ) ds
gdzie f (u; μ, σ) jest funkcją gęstości prawdopodobieństwa:
f (s; μ, σ) = (1 / (σ√ (2π)) Exp (- sdwa/ (2σdwa))
Stała, która mnoży funkcję wykładniczą w funkcji gęstości prawdopodobieństwa, nazywana jest stałą normalizacyjną i została wybrana w taki sposób, że:
N (+ ∞, μ, σ) = 1
Poprzednie wyrażenie zapewnia, że prawdopodobieństwo, że zmienna losowa x wynosi od -∞ do + ∞ wynosi 1, czyli 100% prawdopodobieństwa.
Parametr μ jest średnią arytmetyczną ciągłej zmiennej losowej x y σ odchylenie standardowe lub pierwiastek kwadratowy z wariancji tej samej zmiennej. W zdarzeniu w którym μ = 0 Y σ = 1 mamy wtedy standardowy rozkład normalny lub typowy rozkład normalny:
N (x; μ = 0, σ = 1)
1- Jeśli losowa zmienna statystyczna ma rozkład normalny gęstości prawdopodobieństwa f (s; μ, σ), większość danych skupia się wokół średniej wartości μ i są rozproszone wokół niego w taki sposób, że pomiędzy nimi znajduje się nieco ponad ⅔ danych μ - σ Y μ + σ.
2- Odchylenie standardowe σ to jest zawsze pozytywne.
3- Postać funkcji gęstości fa przypomina dzwonek, dlatego funkcja ta jest często nazywana dzwonkiem Gaussa lub funkcją Gaussa.
4- W rozkładzie Gaussa średnia, mediana i tryb pokrywają się.
5- Punkty przegięcia funkcji gęstości prawdopodobieństwa znajdują się dokładnie w μ - σ Y μ + σ.
6- Funkcja f jest symetryczna względem osi, która przechodzi przez jej wartość średnią μ y ma asymptotycznie zero dla x ⟶ + ∞ i x ⟶ -∞.
7- Im wyższa wartość σ większa dyspersja, szum lub odległość danych wokół średniej wartości. To znaczy do większego σ kształt dzwonu jest bardziej otwarty. Zamiast σ mała oznacza, że kostki są ciasne do środka, a kształt dzwonka jest bardziej zamknięty lub spiczasty.
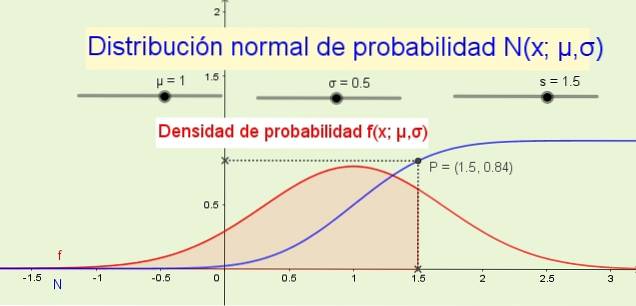
8- Funkcja dystrybucji N (x; μ, σ) wskazuje prawdopodobieństwo, że zmienna losowa jest mniejsza lub równa x. Na przykład na rysunku 1 (powyżej) prawdopodobieństwo P, że zmienna x jest mniejsza lub równa 1,5 wynosi 84% i odpowiada obszarowi pod funkcją gęstości prawdopodobieństwa f (x; μ, σ) od -∞ do x.
9- Jeśli dane mają rozkład normalny, to 68,26% z nich jest pomiędzy μ - σ Y μ + σ.
10-95,44% danych, które mają rozkład normalny, znajduje się pomiędzy μ - 2σ Y μ + 2σ.
11–99,74% danych, które mają rozkład normalny, znajduje się pomiędzy μ - 3σ Y μ + 3σ.
12- Jeśli zmienna losowa x podążaj za dystrybucją N (x; μ, σ), potem zmienna
z = (x - μ) / σ jest zgodny ze standardowym rozkładem normalnym N (z, 0,1).
Zmiana zmiennej x do z Nazywa się to standaryzacją lub typowaniem i jest bardzo przydatne przy stosowaniu tabel rozkładu standardowego do danych, które są zgodne z niestandardowym rozkładem normalnym..
Aby zastosować rozkład normalny, należy przejść przez obliczenie całki gęstości prawdopodobieństwa, co z analitycznego punktu widzenia nie jest łatwe i nie zawsze istnieje program komputerowy, który pozwala na jej numeryczne obliczenie. W tym celu wykorzystuje się tabele wartości znormalizowanych lub znormalizowanych, co jest niczym innym jak rozkładem normalnym w tym przypadku μ = 0 i σ = 1.
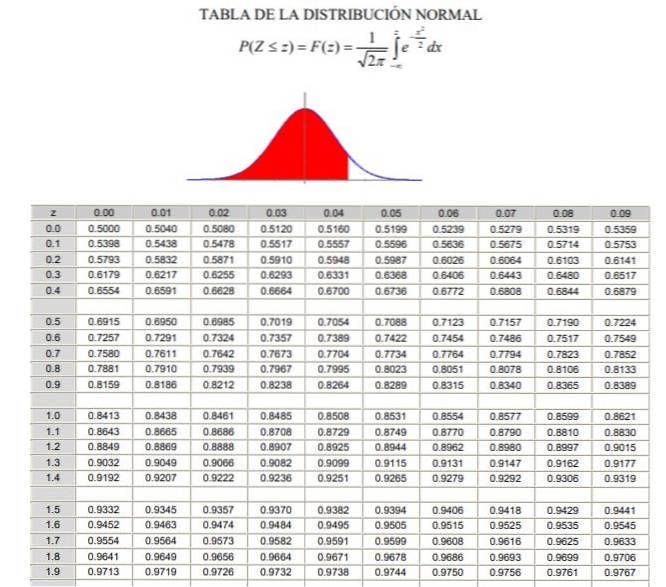
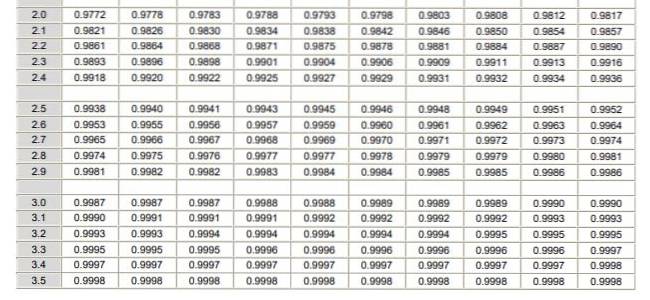
Należy zauważyć, że te tabele nie zawierają wartości ujemnych. Jednak wykorzystując właściwości symetrii funkcji gęstości prawdopodobieństwa Gaussa, można otrzymać odpowiednie wartości. W rozwiązanym ćwiczeniu pokazanym poniżej wskazano użycie tabeli w tych przypadkach.
Załóżmy, że masz zestaw losowych danych x, które mają rozkład normalny o średniej 10 i odchyleniu standardowym 2. Zostaniesz poproszony o znalezienie prawdopodobieństwa, że:
a) Zmienna losowa x jest mniejsza lub równa 8.
b) jest mniejsze lub równe 10.
c) że zmienna x jest poniżej 12.
d) Prawdopodobieństwo, że wartość x zawiera się między 8 a 12.
Rozwiązanie:
a) Aby odpowiedzieć na pierwsze pytanie, wystarczy obliczyć:
N (x; μ, σ)
Z x = 8, μ = 10 Y σ = 2. Zdajemy sobie sprawę, że jest to całka, która nie ma rozwiązania analitycznego w funkcjach elementarnych, ale rozwiązanie jest wyrażone jako funkcja funkcji błędu erf (x).
Z drugiej strony istnieje możliwość rozwiązania całki w postaci numerycznej, co robi wiele kalkulatorów, arkuszy kalkulacyjnych i programów komputerowych, takich jak GeoGebra. Poniższy rysunek przedstawia rozwiązanie numeryczne odpowiadające pierwszemu przypadkowi:
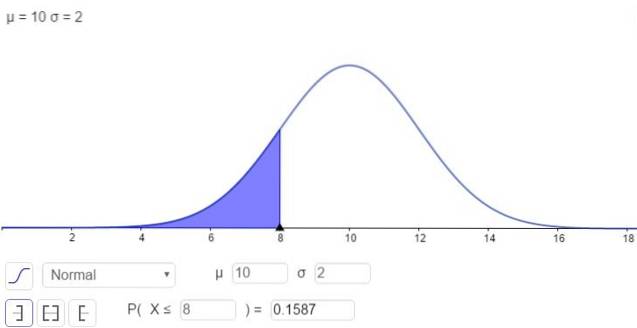
a odpowiedź brzmi, że prawdopodobieństwo, że x jest poniżej 8, wynosi:
P (x ≤ 8) = N (x = 8; μ = 10, σ = 2) = 0,1587
b) W tym przypadku staramy się znaleźć prawdopodobieństwo, że zmienna losowa x jest poniżej średniej, która w tym przypadku jest warta 10. Odpowiedź nie wymaga żadnych obliczeń, ponieważ wiemy, że połowa danych jest poniżej średniej i druga połowa powyżej średniej. Dlatego odpowiedź brzmi:
P (x ≤ 10) = N (x = 10; μ = 10, σ = 2) = 0,5
c) Aby odpowiedzieć na to pytanie, musisz obliczyć N (x = 12; μ = 10, σ = 2), Można to zrobić za pomocą kalkulatora z funkcjami statystycznymi lub oprogramowania takiego jak GeoGebra:
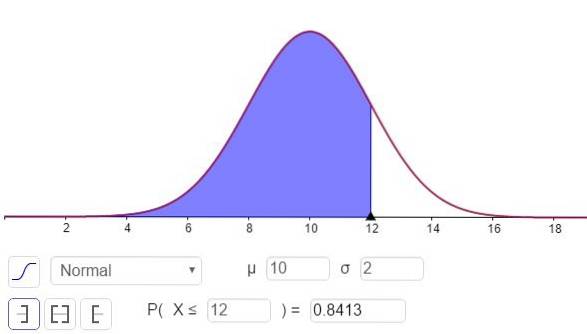
Odpowiedź na część c można zobaczyć na rysunku 3 i jest ona następująca:
P (x ≤ 12) = N (x = 12; μ = 10, σ = 2) = 0,8413.
d) Aby znaleźć prawdopodobieństwo, że zmienna losowa x zawiera się w przedziale od 8 do 12, możemy użyć wyników części a i c w następujący sposób:
P (8 ≤ x ≤ 12) = P (x ≤ 12) - P (x ≤ 8) = 0,8413 - 0,1587 = 0,6826 = 68,26%.
Średnia cena akcji firmy wynosi 25 USD z odchyleniem standardowym 4 USD. Określ prawdopodobieństwo, że:
a) Akcja kosztuje mniej niż 20 $.
b) To ma koszt większy niż 30 USD.
c) Cena wynosi od 20 do 30 USD.
Użyj standardowych tabel rozkładu normalnego, aby znaleźć odpowiedzi.
Rozwiązanie:
Aby skorzystać z tabel, konieczne jest przekazanie do znormalizowanej lub typizowanej zmiennej z:
20 dolarów w znormalizowanej zmiennej równa się z = (20 $ - 25 $) / 4 $ = -5/4 = -1,25 i
30 dolarów w znormalizowanej zmiennej równa się z = (30 $ - 25 $) / 4 USD = +5/4 = +1,25.
a) 20 $ równa się -1,25 w zmiennej znormalizowanej, ale w tabeli nie ma wartości ujemnych, dlatego umieszczamy wartość +1,25, co daje wartość 0,8944.
Jeśli od tej wartości odejmie się 0,5, wynikiem będzie obszar między 0 a 1,25, który, nawiasem mówiąc, jest identyczny (przez symetrię) z polem między -1,25 a 0. Wynik odejmowania to 0,8944 - 0,5 = 0,3944 czyli obszar między -1,25 a 0.
Ale interesujący jest obszar od -∞ do -1,25, który wyniesie 0,5 - 0,3944 = 0,1056. W związku z tym stwierdza się, że prawdopodobieństwo, że cena akcji spadnie poniżej 20 USD, wynosi 10,56%.
b) 30 $ w zmiennej typizowanej z wynosi 1,25. Dla tej wartości w tabeli pojawia się liczba 0,8944, która odpowiada obszarowi od -∞ do +1,25. Obszar między +1,25 a + ∞ wynosi (1 - 0,8944) = 0,1056. Oznacza to, że prawdopodobieństwo, że akcja kosztuje więcej niż 30 USD, wynosi 10,56%.
c) Prawdopodobieństwo, że działanie ma koszt od 20 do 30 USD, będzie obliczane w następujący sposób:
100% -10,56% - 10,56% = 78,88%



Jeszcze bez komentarzy