
Plik skumulowana częstotliwość jest sumą bezwzględnych częstotliwości f, od najniższej do takiej, która odpowiada określonej wartości zmiennej. Z kolei częstotliwość bezwzględna to liczba przypadków, w których obserwacja pojawia się w zbiorze danych.
Oczywiście badana zmienna musi być sortowalna. A ponieważ skumulowaną częstotliwość uzyskuje się przez dodanie częstotliwości bezwzględnych, okazuje się, że skumulowana częstotliwość do ostatnich danych musi pokrywać się z ich sumą. W przeciwnym razie w obliczeniach wystąpi błąd.

Zwykle skumulowana częstotliwość jest oznaczona jako F.ja (lub czasami nja), aby odróżnić ją od częstotliwości bezwzględnej fja i ważne jest, aby dodać dla niego kolumnę w tabeli, w której są zorganizowane dane, znanej jako Tabela częstotliwości.
Ułatwia to między innymi śledzenie, ile danych zostało policzonych do określonej obserwacji..
A Fja jest również znany jako bezwzględna skumulowana częstotliwość. Jeśli podzielimy przez łączne dane, otrzymamy rozszerzenie względna skumulowana częstotliwość, których ostateczna suma musi być równa 1.
Indeks artykułów
Skumulowana częstotliwość danej wartości zmiennej Xja jest sumą bezwzględnych częstotliwości f wszystkich wartości mniejszych lub równych:
faja = f1 + fadwa + fa3 +... fja
Dodając wszystkie częstotliwości bezwzględne, uzyskuje się całkowitą liczbę danych N, czyli:
fa1 + fadwa + fa3 +… + F.n = N
Poprzednia operacja jest podsumowana za pomocą symbolu sumowania:
∑ F.ja = N
Można również kumulować następujące częstotliwości:
-Względna częstotliwość: uzyskuje się dzieląc bezwzględną częstotliwość fja między danymi ogółem N:
far = fja / N
Jeśli dodamy względne częstotliwości od najniższej do odpowiadającej pewnej obserwacji, otrzymamy skumulowana częstotliwość względna. Ostatnia wartość musi być równa 1.
-Procentowa skumulowana częstotliwość względna: skumulowana częstotliwość względna jest mnożona przez 100%.
fa% = (fja / N) x 100%
Częstotliwości te są przydatne do opisania zachowania danych, na przykład podczas znajdowania miar tendencji centralnej.
Aby uzyskać skumulowaną częstotliwość, konieczne jest uporządkowanie danych i uporządkowanie ich w tabeli częstotliwości. Procedura jest zilustrowana w następującej sytuacji praktycznej:
-W sklepie internetowym sprzedającym telefony komórkowe rekord sprzedaży określonej marki w marcu wykazał następujące wartości dzienne:
1; dwa; 1; 3; 0; 1; 0; dwa; 4; dwa; 1; 0; 3; 3; 0; 1; dwa; 4; 1; dwa; 3; dwa; 3; 1; dwa; 4; dwa; 1; 5; 5; 3
Zmienna to liczba sprzedawanych telefonów dziennie i to jest ilościowe. Prezentowane w ten sposób dane nie są tak łatwe do zinterpretowania, np. Właściciele sklepu mogą być zainteresowani tym, czy jest jakiś trend, jak np. Dni tygodnia, w których sprzedaż tej marki jest wyższa..
Informacje takie i nie tylko można uzyskać, przedstawiając dane w uporządkowany sposób i określając częstotliwości..
Aby obliczyć skumulowaną częstotliwość, dane są najpierw uporządkowane:
0; 0; 0; 0; 1; 1; 1; 1; 1; 1; 1; 1; dwa; dwa; dwa; dwa; dwa; dwa; dwa; dwa; 3; 3; 3; 3; 3; 3; 4; 4; 4; 5; 5
Następnie budowana jest tabela z następującymi informacjami:
-Pierwsza kolumna po lewej stronie z liczbą sprzedanych telefonów od 0 do 5 w kolejności rosnącej.
-Druga kolumna: częstotliwość bezwzględna, czyli liczba dni, w których sprzedano 0 telefonów, 1 telefon, 2 telefony itd.
-Trzecia kolumna: skumulowana częstotliwość, składająca się z sumy poprzedniej częstotliwości i częstotliwości danych, które mają być brane pod uwagę.
Ta kolumna zaczyna się od pierwszych danych w kolumnie częstotliwości bezwzględnej, w tym przypadku jest to 0. Aby uzyskać następną wartość, dodaj ją do poprzedniej. Trwa w ten sposób, aż do osiągnięcia ostatnich danych zgromadzonej częstotliwości, które muszą pokrywać się z danymi całkowitymi.
Poniższa tabela przedstawia zmienną „liczbę telefonów sprzedanych w ciągu dnia”, jej bezwzględną częstotliwość oraz szczegółowe obliczenia skumulowanej częstotliwości.
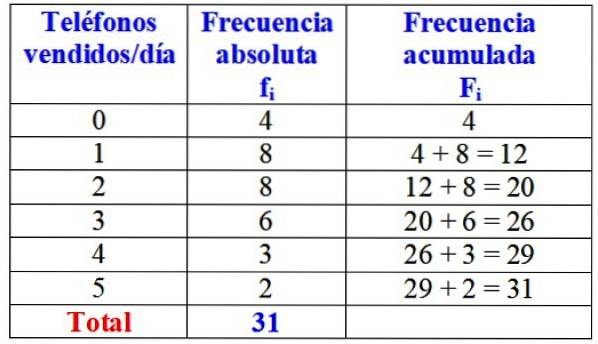
Na pierwszy rzut oka można by stwierdzić, że w danej marce prawie zawsze sprzedaje się jeden lub dwa telefony dziennie, ponieważ najwyższa częstotliwość bezwzględna to 8 dni, co odpowiada tym wartościom zmiennej. Tylko przez 4 dni miesiąca nie sprzedali ani jednego telefonu.
Jak wspomniano, tabela jest łatwiejsza do zbadania niż pierwotnie zebrane indywidualne dane.
Skumulowany rozkład częstotliwości to tabela pokazująca bezwzględne częstości, skumulowane częstości, skumulowane względne częstości i skumulowane częstości procentowe..
Chociaż istnieje zaleta organizowania danych w tabeli takiej jak poprzednia, jeśli liczba danych jest bardzo duża, może nie wystarczyć ich uporządkowanie, jak pokazano powyżej, ponieważ jeśli występuje wiele częstotliwości, nadal jest to trudne. interpretować.
Problem można rozwiązać, budując plik rozkład częstotliwości interwałami, przydatna procedura, gdy zmienna przyjmuje dużą liczbę wartości lub jest zmienną ciągłą.
Tutaj wartości są pogrupowane w przedziały o równej amplitudzie, tzw klasa. Zajęcia charakteryzują się:
-Limit zajęć: to skrajne wartości każdego przedziału, są dwa, górna granica i dolna granica. Ogólnie rzecz biorąc, górna granica nie należy do przedziału, ale do następnego, podczas gdy dolna granica należy.
-Ocena klasy: jest środkiem każdego przedziału i jest traktowany jako jego reprezentatywna wartość.
-Szerokość klasy: Oblicza się go, odejmując wartość największych i najmniejszych danych (zakres) i dzieląc przez liczbę klas:
Szerokość klasy = zakres / liczba klas
Szczegółowy opis rozkładu częstotliwości znajduje się poniżej..
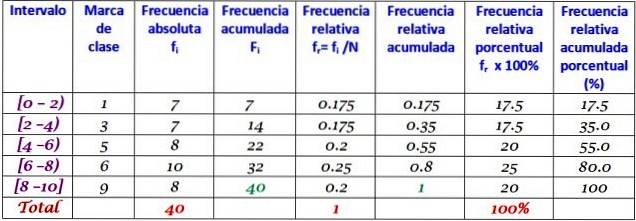
Ten zestaw danych odpowiada 40 punktom z testu matematycznego w skali od 0 do 10:
0; 0; 0; 1; 1; 1; 1; dwa; dwa; dwa; 3; 3; 3; 3; 4; 4; 4; 4; 5; 5; 5; 5; 6; 6; 6; 6; 7; 7; 7; 7; 7; 7; 8; 8; 8; 9; 9; 9; 10; 10.
Rozkład częstotliwości może być utworzony z pewnej liczby klas, na przykład 5 klas. Należy pamiętać, że przy korzystaniu z wielu klas dane nie są łatwe do zinterpretowania i gubi się sens przeprowadzania grupowania.
A jeśli wręcz przeciwnie, są one pogrupowane w bardzo nieliczne, informacje są rozcieńczane, a część z nich jest tracona. Wszystko zależy od ilości posiadanych danych.
W tym przykładzie dobrze jest mieć dwie oceny w każdym przedziale, ponieważ jest 10 wyników i zostanie utworzonych 5 klas. Zakres to odejmowanie między najwyższą a najniższą oceną, przy czym szerokość klasy wynosi:
Szerokość klasy = (10-0) / 5 = 2
Przedziały są zamknięte po lewej stronie i otwarte po prawej (z wyjątkiem ostatniego), co jest symbolizowane odpowiednio nawiasami kwadratowymi i nawiasami. Wszystkie mają tę samą szerokość, ale nie jest to obowiązkowe, chociaż jest to najczęściej.
Każdy przedział zawiera określoną ilość elementów lub bezwzględną częstotliwość, aw następnej kolumnie jest skumulowana częstotliwość, w której jest przenoszona suma. Tabela pokazuje również względną częstotliwość fr (częstotliwość bezwzględna między całkowitą liczbą danych) a procentową częstotliwością względną fr × 100%.
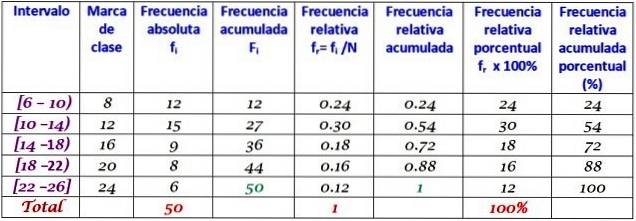
Jedna firma codziennie dzwoniła do swoich klientów przez pierwsze dwa miesiące roku. Dane są następujące:
6, 12, 7, 15, 13, 18, 20, 25, 12, 10, 8, 13, 15, 6, 9, 18, 20, 24, 12, 7, 10, 11, 13, 9, 12, 15, 18, 20, 13, 17, 23, 25, 14, 18, 6, 14, 16, 9, 6, 10, 12, 20, 13, 17, 14, 26, 7, 12, 24, 7
Pogrupuj w 5 klas i zbuduj tabelę z rozkładem częstotliwości.
Szerokość klasy to:
(26-6) / 5 = 4
Spróbuj to rozgryźć, zanim zobaczysz odpowiedź.



Jeszcze bez komentarzy