Plik miary tendencji centralnej, rozproszenia i pozycji, to wartości używane do prawidłowej interpretacji zestawu danych statystycznych. Można je opracować bezpośrednio, ponieważ pochodzą z badań statystycznych lub można je zorganizować w grupy o równej częstotliwości, ułatwiając analizę..
Pozwalają dowiedzieć się, wokół jakich wartości grupowane są dane statystyczne.
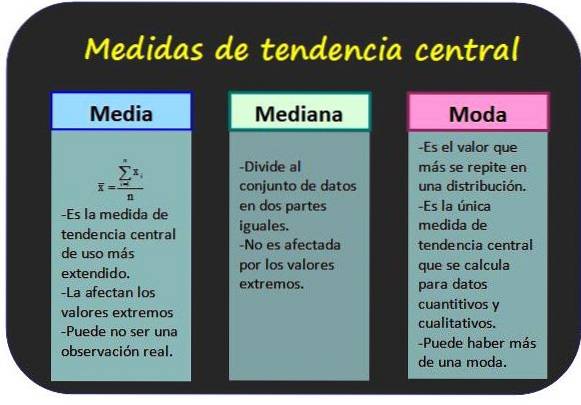
Jest również znany jako średnia wartości zmiennej i jest uzyskiwany przez dodanie wszystkich wartości i podzielenie wyniku przez całkowitą liczbę danych.
Niech będzie zmienną x, której mamy n danych bez porządkowania i grupowania, a jej średnią arytmetyczną oblicza się w następujący sposób:
A w podsumowaniu:
Właściciele karczmy dla turystów górskich chcą wiedzieć, ile średnio dni przebywają w nich goście. W tym celu prowadzono ewidencję dni trwania 20 grup turystów, uzyskując następujące dane:
1; 1; dwa; dwa; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; dwa; dwa; 3; 4; 1
Średnia liczba dni pobytu turystów to:
Jeśli dane zmiennej są zorganizowane w tabeli częstotliwości bezwzględnych fja a centra klas to x1, xdwa,..., xn, średnią oblicza się ze wzoru:
Podsumowując:
Mediana grupy n wartości zmiennej x jest centralną wartością grupy, pod warunkiem, że wartości są uporządkowane w kolejności rosnącej. W ten sposób połowa wszystkich wartości jest mniejsza niż tryb, a druga połowa jest większa..
Mogą wystąpić następujące przypadki:
-Liczba n wartości zmiennej x dziwny: mediana to wartość znajdująca się w środku grupy wartości:
-Liczba n wartości zmiennej x para: w tym przypadku medianę oblicza się jako średnią dwóch centralnych wartości grupy danych:
Aby znaleźć medianę danych z hostelu turystycznego, należy je najpierw uporządkować od najniższej do najwyższej:
1; 1; 1; 1; 1; 1; 1; dwa; dwa; dwa; dwa; 3; 3; 3; 4; 4; 4; 4; 5; 5
Liczba danych jest parzysta, dlatego istnieją dwa główne dane: X10 i Xjedenaście a ponieważ oba są warte 2, ich średnia też jest.
Mediana = 2
Stosowany jest następujący wzór:
Symbole we wzorze oznaczają:
-c: szerokość przedziału zawierającego medianę
-bM: dolna granica tego samego przedziału
-fam: liczba obserwacji zawartych w przedziale, do którego należy mediana.
-n: dane ogółem.
-faBM: liczba obserwacji przed przedziału zawierającego medianę.
Trybem dla danych niezgrupowanych jest wartość o największej częstotliwości, natomiast dla danych zgrupowanych jest to klasa o największej częstotliwości. Za najbardziej reprezentatywne dane lub klasę dystrybucji uważa się modę.
Dwie ważne cechy tej miary to to, że zbiór danych może mieć więcej niż jeden tryb, a tryb można określić zarówno dla danych ilościowych, jak i jakościowych..
Kontynuując dane z paradoru turystycznego, najczęściej powtarza się 1, dlatego najczęściej turyści przebywają w paradorze 1 dzień.
Miary dyspersji opisują, jak skupione są dane wokół miar centralnych.
Oblicza się go, odejmując największe i najmniejsze dane. Jeśli ta różnica jest duża, oznacza to, że dane są rozproszone, podczas gdy małe wartości wskazują, że dane są bliskie średniej..
Zakres danych ośrodka turystycznego to:
Zakres = 5-1 = 4
Aby znaleźć wariancję sdwa Najpierw należy znać średnią arytmetyczną, a następnie oblicza się kwadratową różnicę między każdą częścią danych a średnią, wszystkie z nich dodaje się i dzieli przez całkowitą liczbę obserwacji. Te różnice są znane jako odchylenia.
Wariancja, która jest zawsze dodatnia (lub zero), wskazuje, jak daleko obserwacje są od średniej: jeśli wariancja jest duża, wartości są bardziej rozproszone niż wtedy, gdy wariancja jest mała.
Wariancja dla danych z hostelu turystycznego wynosi:
1; 1; dwa; dwa; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; dwa; dwa; 3; 4; 1
Aby znaleźć wariancję zgrupowanego zbioru danych, wymagane są: i) średnia, ii) częstotliwość fja czyli łączne dane w każdej klasie oraz iii) xja lub wartość klasy:
Odchylenie standardowe jest dodatnim pierwiastkiem kwadratowym z wariancji, więc ma przewagę nad wariancją: występuje w tych samych jednostkach co badana zmienna, dzięki czemu masz bardziej bezpośredni obraz tego, jak blisko lub daleko jest ta zmienna od średniej.
Określa się go po prostu poprzez znalezienie pierwiastka kwadratowego z wariancji dla niezgrupowanych danych:
Odchylenie standardowe dla danych z hostelu turystycznego wynosi:
s = √ (sdwa) = √1,95 = 1,40
Oblicza się go, znajdując pierwiastek kwadratowy z wariancji dla danych zgrupowanych:
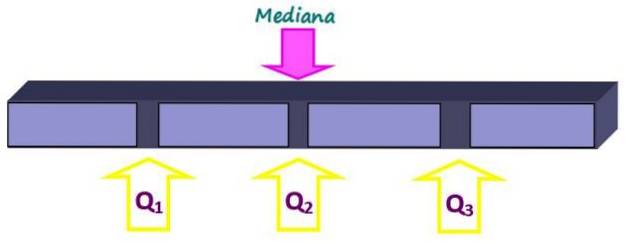
Miary pozycji dzielą uporządkowany zestaw danych na części o jednakowej wielkości. Mediana, oprócz tego, że jest miarą tendencji centralnej, jest również miarą położenia, ponieważ dzieli całość na dwie równe części. Ale mniejsze części można uzyskać za pomocą kwartyli, decyli i percentyli.
Kwartyle dzielą zbiór na cztery równe części, z których każda zawiera 25% danych. Są oznaczone jako Q1, Qdwa i Q3 a mediana to kwartyl Qdwa. W ten sposób 25% danych znajduje się poniżej kwartylu Q.1, 50% poniżej kwartylu Q.dwa lub mediana i 75% poniżej kwartylu Q.3.
Dane są uporządkowane, a całość podzielona na 4 grupy z taką samą liczbą danych w każdej. Pozycję pierwszego kwartylu wyznacza:
Q1 = (n + 1) / 4
Gdzie n to dane ogółem. Jeśli wynik jest liczbą całkowitą, dane odpowiadające tej pozycji są zlokalizowane, ale jeśli są dziesiętne, dane odpowiadające części całkowitej są uśredniane z następną lub dla większej dokładności są interpolowane liniowo między wspomnianymi danymi.
Pozycja pierwszego kwartylu Q1 dla danych ośrodka turystycznego jest:
Q1 = (n + 1) / 4 = (20 + 1) / 4 = 5,25
Jest to pozycja 1 kwartylu, a ponieważ wynik jest dziesiętny, przeszukiwane są dane X.5 i X6, które są odpowiednio X5 = 1 i X6 = 1 i są uśredniane, co daje:
Pierwszy kwartyl = 1
1; 1; 1; 1; 1; 1; 1; dwa; dwa; dwa; dwa; 3; 3; 3; 4; 4; 4; 4; 5; 5.
Pozycja drugiego kwartylu Qdwa to jest:
Qdwa = 2 (n + 1) / 4 = 10,5
Jaka jest średnia między X10 i Xjedenaście i odpowiada medianie:
Drugi kwartyl = mediana = 2
Pozycję trzeciego kwartylu oblicza się ze wzoru:
Q3 = 3 (n + 1) / 4 = 3 (20 + 1) / 4 = 15,75
Jest również dziesiętny, dlatego X jest uśrednianypiętnaście i X16:
1; 1; 1; 1; 1; 1; 1; dwa; dwa; dwa; dwa; 3; 3; 3; 4; 4; 4; 4; 5; 5.
Ale ponieważ oba są warte 4:
Trzeci kwartyl = 4
Ogólny wzór na położenie kwartyli w niezgrupowanych danych jest następujący:
Qk = k (n + 1) / 4
Przy k = 1,2,3.
Obliczane są podobnie do mediany:

Objaśnienie symboli:
-bQ: dolna granica przedziału zawierającego kwartyl
-c: szerokość tego przedziału
-faco: liczba obserwacji zawartych w przedziale kwartylowym.
-n: dane ogółem.
-faBQ: liczba danych przed przedziału zawierającego kwartyl.
Decyle i percentyle dzielą zestaw danych odpowiednio na 10 równych części i 100 równych części, a ich obliczenie odbywa się w podobny sposób, jak w przypadku kwartyli.
Wzory stosuje się odpowiednio:
rek = k (n + 1) / 10
Przy k = 1, 2, 3… 9.
Decile D.5 musi być równa medianie.
P.k = k (n + 1) / 100
Przy k = 1, 2, 3… 99.
Percentyl P.pięćdziesiąt musi być równa medianie.
Na przykładzie schroniska turystycznego pozycja D3 to jest:
re3 = 3 (20 + 1) / 10 = 6,3
Ponieważ jest to liczba dziesiętna, X jest uśredniane6 i X7, oba równe 1:
1; 1; 1; 1; 1; 1; 1; dwa; dwa; dwa; dwa; 3; 3; 3; 4; 4; 4; 4; 5; 5
Oznacza to, że 3 dziesiąte danych znajduje się poniżej X7 = 1, a pozostałe powyżej.
Wzory są analogiczne do formuł kwartyli. D jest używany do oznaczania decyli, a P do percentyli, a symbole są interpretowane podobnie:
Gdy dane są rozmieszczone symetrycznie, a dystrybucja jest unimodalna, obowiązuje reguła o nazwie Zasada empiryczna lub zasada 68 - 95 - 99, która grupuje je w następujących przedziałach:
W jakim przedziale jest 95% danych z paradora turystycznego?
Znajdują się one w przedziale: [2,5–1,40; 2,5 + 1,40] = [1,1; 3.9].



Jeszcze bez komentarzy