Plik model relacyjny baz danych to metoda strukturyzowania danych za pomocą relacji, przy użyciu struktur przypominających siatkę, składających się z kolumn i wierszy. Jest to koncepcyjna zasada relacyjnych baz danych. Zaproponował go Edgar F. Codd w 1969 roku.
Od tego czasu stał się dominującym modelem bazy danych dla aplikacji biznesowych w porównaniu z innymi modelami baz danych, takimi jak hierarchiczne, sieciowe i obiektowe..
Codd nie miał pojęcia, jak niezwykle ważna i wpływowa będzie jego praca jako platformy dla relacyjnych baz danych. Większość ludzi jest dobrze zaznajomiona z fizycznym wyrażeniem relacji w bazie danych: tabeli.
Model relacyjny jest zdefiniowany jako baza danych, która umożliwia grupowanie elementów danych w jednej lub kilku niezależnych tabelach, które mogą być ze sobą powiązane za pomocą pól wspólnych dla każdej powiązanej tabeli..
Indeks artykułów
Tabela bazy danych jest podobna do arkusza kalkulacyjnego. Jednak relacje, które można utworzyć między tabelami, pozwalają relacyjnej bazie danych na wydajne przechowywanie dużej ilości danych, które można skutecznie odzyskać..
Celem modelu relacyjnego jest zapewnienie deklaratywnej metody określania danych i zapytań: użytkownicy bezpośrednio deklarują, jakie informacje zawiera baza danych i jakie informacje chcą od niej.
Z drugiej strony pozwolili oprogramowaniu systemu zarządzania bazą danych odpowiadać za opisywanie struktur danych do przechowywania i procedurę wyszukiwania w celu udzielenia odpowiedzi na zapytania..
Większość relacyjnych baz danych używa języka SQL do wykonywania zapytań i definiowania danych. Obecnie istnieje wiele systemów zarządzania relacyjnymi bazami danych lub RDBMS (Relational Data Base Management System), takich jak Oracle, IBM DB2 i Microsoft SQL Server.
- Wszystkie dane są koncepcyjnie reprezentowane jako uporządkowane rozmieszczenie danych w wierszach i kolumnach, zwane relacją lub tabelą.
- Każda tabela musi mieć nagłówek i treść. Nagłówek to po prostu lista kolumn. Treść to zestaw danych wypełniających tabelę, uporządkowany w wierszach.
- Wszystkie wartości są skalarami. Oznacza to, że w dowolnej pozycji wiersza / kolumny w tabeli jest tylko jedna wartość.
Poniższy rysunek przedstawia tabelę z nazwami jej podstawowych elementów, które składają się na kompletną strukturę.

Każdy wiersz danych jest krotką, nazywaną również rekordem. Każdy wiersz jest n-krotką, ale „n-” jest generalnie odrzucane.
Każda kolumna krotki nazywana jest atrybutem lub polem. Kolumna reprezentuje zestaw wartości, które może mieć określony atrybut.
Każdy wiersz zawiera co najmniej jedną kolumnę zwaną kluczem tabeli. Ta połączona wartość jest unikalna dla wszystkich wierszy w tabeli. Za pomocą tego klucza każda krotka zostanie jednoznacznie zidentyfikowana. Oznacza to, że klucza nie można powielić. Nazywa się to kluczem podstawowym.
Z drugiej strony klucz obcy lub pomocniczy to pole w tabeli, które odwołuje się do klucza podstawowego innej tabeli. Służy do odwoływania się do tabeli podstawowej.
Projektując model relacyjny, definiujesz pewne warunki, które muszą być spełnione w bazie danych, zwane regułami integralności.
Klucz podstawowy musi być unikatowy dla wszystkich krotek i nie może mieć wartości null. W przeciwnym razie nie będziesz w stanie jednoznacznie zidentyfikować wiersza.
W przypadku klucza wielokolumnowego żadna z tych kolumn nie może zawierać wartości NULL.
Każda wartość klucza obcego musi odpowiadać wartości klucza podstawowego tabeli, do której się odwołuje lub tabeli podstawowej.
Wiersz z kluczem obcym można wstawić do tabeli dodatkowej tylko wtedy, gdy ta wartość istnieje w tabeli podstawowej.
Jeśli wartość klucza zmieni się w tabeli nadrzędnej, poprzez aktualizację lub usunięcie wiersza, wszystkie wiersze w tabelach podrzędnych z tym kluczem obcym powinny zostać odpowiednio zaktualizowane lub usunięte.
Aby móc przechowywać je w bazie danych, należy zebrać niezbędne dane. Te dane są podzielone na różne tabele.
Dla każdej kolumny należy wybrać odpowiedni typ danych. Na przykład: liczby całkowite, liczby zmiennoprzecinkowe, tekst, data itp..
Dla każdej tabeli należy wybrać kolumnę (lub kilka kolumn) jako klucz podstawowy, który będzie jednoznacznie identyfikował każdy wiersz w tabeli. Klucz podstawowy służy również do odwoływania się do innych tabel.
Baza danych składająca się z niezależnych i niepowiązanych tabel ma niewielki cel.
Najważniejszym aspektem projektowania relacyjnej bazy danych jest identyfikacja relacji między tabelami. Typy relacji to:
W bazie danych „Class Listing” nauczyciel może prowadzić zero lub więcej zajęć, podczas gdy zajęcia są prowadzone przez jednego nauczyciela. Ten typ relacji jest znany jako jeden do wielu..
Tej relacji nie można przedstawić w jednej tabeli. W bazie danych „Lista zajęć” możesz mieć tabelę Nauczyciele, w której przechowywane są informacje o nauczycielach.
Aby przechowywać zajęcia nauczane przez każdego nauczyciela, możesz utworzyć dodatkowe kolumny, ale napotkasz problem: ile kolumn utworzyć.
Z drugiej strony, jeśli masz tabelę o nazwie Classes, która przechowuje informacje o klasie, możesz utworzyć dodatkowe kolumny do przechowywania informacji o nauczycielu..
Ponieważ jednak nauczyciel może uczyć na wielu zajęciach, jego dane byłyby zduplikowane w wielu wierszach tabeli Zajęcia.
Dlatego należy zaprojektować dwie tabele: tabelę Classes do przechowywania informacji o zajęciach z Class_Id jako kluczem podstawowym oraz tabelę Teachers do przechowywania informacji o nauczycielach, z kluczem Teacher_Id jako kluczem podstawowym..
Następnie można utworzyć relację jeden do wielu, przechowując klucz podstawowy tabeli Master (Master_Id) w tabeli Classes, jak pokazano poniżej.
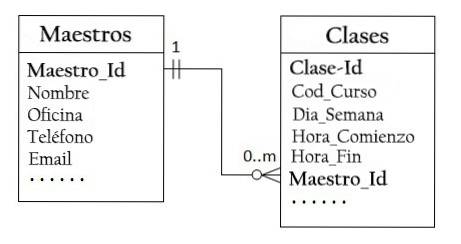
Kolumna Master_Id w tabeli Classes jest nazywana kluczem obcym lub kluczem pomocniczym.
Dla każdej wartości Master_Id w tabeli Master może znajdować się zero lub więcej wierszy w tabeli Classes. Dla każdej wartości Class_Id w tabeli Classes istnieje tylko jeden wiersz w tabeli Teachers.
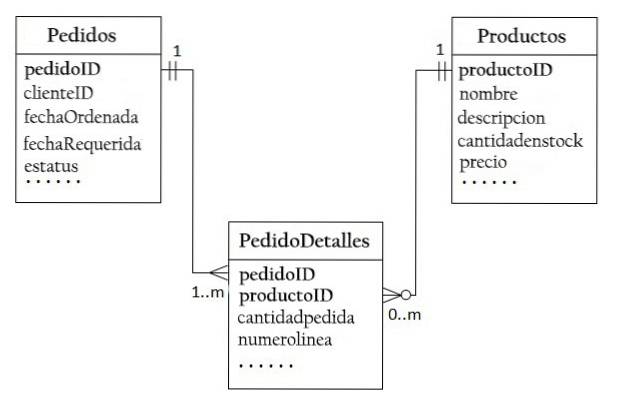
W bazie danych „Sprzedaż produktów” zamówienie klienta może zawierać wiele produktów, a jeden produkt może występować w wielu zamówieniach. Ten typ relacji jest znany jako „wiele do wielu”.
Bazę danych „Sprzedaż produktów” można uruchomić z dwiema tabelami: Produkty i Zamówienia. Tabela Produkty zawiera informacje o produktach, z kluczem podstawowym productID.
Z drugiej strony tabela Zamówienia zawiera zamówienia klienta z kluczem podstawowym orderID.
Nie możesz przechowywać zamówionych produktów w tabeli Zamówienia, ponieważ nie wiesz, ile kolumn zarezerwować dla produktów. Z tego samego powodu nie można również przechowywać zamówień w tabeli Produkty.
Aby obsługiwać relację wiele do wielu, musisz utworzyć trzecią tabelę, zwaną tabelą łączenia (OrderDetails), w której każdy wiersz reprezentuje element w określonej kolejności.
W tabeli OrderDetails klucz podstawowy składa się z dwóch kolumn: orderID i productID, które jednoznacznie identyfikują każdy wiersz.
Kolumny orderID i productID w tabeli OrderDetails służą do odwoływania się do tabel Zamówienia i Produkty. Dlatego są również kluczami obcymi w tabeli OrderDetails..
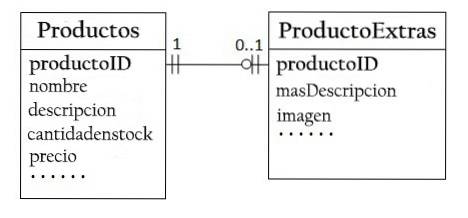
W bazie danych „Sprzedaż produktów” produkt może mieć opcjonalne informacje, takie jak dodatkowy opis i jego zdjęcie. Pozostawienie go w tabeli Produkty wygenerowałoby wiele pustych miejsc.
W związku z tym można utworzyć inną tabelę (ProductExtras) do przechowywania opcjonalnych danych. Dla produktów z opcjonalnymi danymi zostanie utworzony tylko jeden rekord.
Dwie tabele, Products i ProductExtras, mają relację jeden do jednego. Dla każdego wiersza w tabeli Products istnieje maksymalnie jeden wiersz w tabeli ProductExtras. Ten sam identyfikator produktu musi być używany jako klucz podstawowy dla obu tabel.
W modelu relacyjnej bazy danych zmiany w strukturze bazy danych nie wpływają na dostęp do danych.
Gdy możliwe jest wprowadzenie zmian w strukturze bazy danych bez wpływu na zdolność DBMS do dostępu do danych, można powiedzieć, że uzyskano niezależność strukturalną.
Model relacyjnej bazy danych jest koncepcyjnie jeszcze prostszy niż model hierarchicznej lub sieciowej bazy danych.
Ponieważ model relacyjnej bazy danych uwalnia projektanta od szczegółów dotyczących fizycznego przechowywania danych, projektanci mogą skupić się na logicznym widoku bazy danych.
Model relacyjnej bazy danych zapewnia zarówno niezależność danych, jak i niezależność od struktury, co sprawia, że projektowanie, konserwacja, administrowanie i użytkowanie bazy danych jest znacznie łatwiejsze niż w przypadku innych modeli..
Obecność bardzo wydajnej, elastycznej i łatwej w użyciu pojemności zapytań jest jednym z głównych powodów ogromnej popularności modelu relacyjnej bazy danych.
Język zapytań modelu relacyjnej bazy danych, zwany Structured Query Language (SQL), sprawia, że zapytania ad-hoc stają się rzeczywistością. SQL to język czwartej generacji (4GL).
4GL pozwala użytkownikowi określić, co należy zrobić, bez określania, jak należy to zrobić. W ten sposób, korzystając z SQL, użytkownicy mogą określić, jakich informacji chcą i pozostawić szczegóły dotyczące sposobu pobierania informacji do bazy danych.
Model relacyjnej bazy danych ukrywa złożoność jego implementacji oraz szczegóły fizycznego przechowywania danych użytkownika.
Aby to zrobić, systemy relacyjnych baz danych potrzebują komputerów z wydajniejszym sprzętem i urządzeniami do przechowywania danych..
Dlatego RDBMS potrzebuje wydajnych maszyn do płynnego działania. Ponieważ jednak moc obliczeniowa nowoczesnych komputerów rośnie wykładniczo, zapotrzebowanie na większą moc obliczeniową w dzisiejszym scenariuszu nie jest już bardzo dużym problemem..
Relacyjna baza danych jest łatwa w projektowaniu i obsłudze. Użytkownicy nie muszą znać skomplikowanych szczegółów dotyczących fizycznego przechowywania danych. Nie muszą wiedzieć, w jaki sposób dane są faktycznie przechowywane, aby uzyskać do nich dostęp.
Ta łatwość projektowania i użytkowania może prowadzić do opracowywania i wdrażania źle zaprojektowanych systemów zarządzania bazami danych. Ponieważ baza danych jest wydajna, te nieefektywności projektowe nie wyjdą na jaw, gdy baza danych jest projektowana i gdy jest tylko niewielka ilość danych.
Wraz z rozwojem bazy danych źle zaprojektowane bazy danych spowalniają system i prowadzą do obniżenia wydajności i uszkodzenia danych..
Jak wspomniano wcześniej, systemy relacyjnych baz danych są łatwe we wdrożeniu i użytkowaniu. Stworzy to sytuację, w której zbyt wiele osób lub działów utworzy własne bazy danych i aplikacje..
Te wyspy informacji uniemożliwiają integrację informacji, która jest niezbędna dla sprawnego i wydajnego funkcjonowania organizacji..
Te indywidualne bazy danych będą również powodować problemy, takie jak niespójność danych, powielanie danych, nadmiarowość danych itp..
Załóżmy, że baza danych składa się z tabel Dostawcy, Części i Przesyłki. Struktura tabel i niektórych przykładowych rekordów jest następująca:
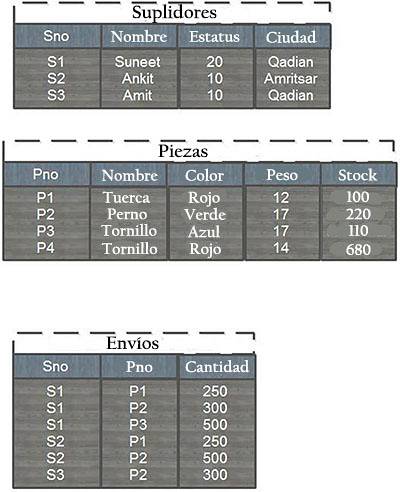
Każdy wiersz w tabeli Dostawcy jest identyfikowany za pomocą unikalnego numeru dostawcy (SNo), który jednoznacznie identyfikuje każdy wiersz w tabeli. Podobnie każda część ma unikalny numer części (PNo).
Ponadto w tabeli Przesyłki nie może istnieć więcej niż jedna przesyłka dla danej kombinacji Dostawca / Część, ponieważ ta kombinacja jest kluczem podstawowym przesyłek, który służy jako tabela sumująca, ponieważ jest to relacja wiele do wielu..
Związek między tabelami części i przesyłek jest określony przez wspólne posiadanie pola PNo (numer części), a związek między dostawcami a wysyłkami wynika z posiadania wspólnego pola SNo (numer dostawcy).
Analizując tabelę wysyłek, można uzyskać informację, że wysyłanych jest łącznie 500 orzechów od dostawców Suneet i Ankit, po 250 sztuk..
Podobnie, łącznie 1100 śrub zostało wysłanych od trzech różnych dostawców. 500 niebieskich śrub zostało wysłanych od dostawcy Suneet. Brak dostaw czerwonych śrub.

Jeszcze bez komentarzy