Plik Dystrybucja F. o Rozkład Fishera-Snedecora to ten używany do porównania wariancji dwóch różnych lub niezależnych populacji, z których każda ma rozkład normalny.
Rozkład, który następuje po wariancji zbioru próbek z pojedynczej populacji normalnej, to rozkład chi-kwadrat (Χdwa) stopnia n-1, jeśli każda z próbek w zestawie ma n elementów.
Aby porównać wariancje dwóch różnych populacji, konieczne jest zdefiniowanie a statystyczny, to znaczy pomocnicza zmienna losowa, która pozwala nam rozróżnić, czy obie populacje mają tę samą wariancję.
Wspomniana zmienna pomocnicza może być bezpośrednio ilorazem wariancji próby każdej populacji, w którym to przypadku, jeśli wspomniany iloraz jest bliski jedności, istnieje dowód, że obie populacje mają podobne wariancje.
Indeks artykułów
Statystyka zmiennej losowej F lub F zaproponowana przez Ronalda Fishera (1890 - 1962) jest najczęściej używaną do porównywania wariancji dwóch populacji i jest definiowana w następujący sposób:
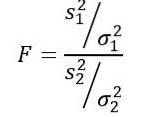
Bycie sdwa wariancja próby i σdwa wariancja populacji. Aby rozróżnić każdą z dwóch grup populacji, stosuje się odpowiednio indeksy dolne 1 i 2..
Wiadomo, że rozkład chi-kwadrat z (n-1) stopniami swobody jest tym, który następuje po zmiennej pomocniczej (lub statystycznej) zdefiniowanej poniżej:
Xdwa = (n-1) sdwa / σdwa.
Dlatego statystyka F ma rozkład teoretyczny określony przez następujący wzór:
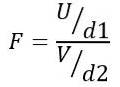
Istota LUB rozkład chi-kwadrat z d1 = n1 - 1 stopnie swobody dla populacji 1 i V rozkład chi-kwadrat z d2 = n2 - 1 stopnie swobody dla populacji 2.
Tak zdefiniowany iloraz jest nowym rozkładem prawdopodobieństwa, znanym jako Dystrybucja F. z d1 stopnie swobody w liczniku i d2 stopnie swobody w mianowniku.
Średnią rozkład F oblicza się w następujący sposób:
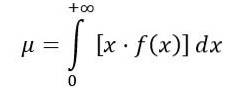
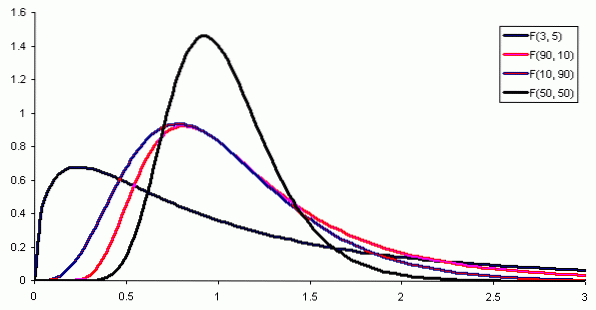
Gdzie f (x) jest gęstością prawdopodobieństwa rozkładu F, co pokazano na rysunku 1 dla różnych kombinacji parametrów lub stopni swobody.
Możemy zapisać gęstość prawdopodobieństwa f (x) jako funkcję funkcji Γ (funkcja gamma):
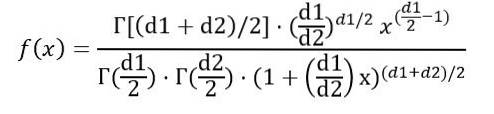
Po wykonaniu całki wskazanej powyżej można wywnioskować, że średnia rozkładu F wraz ze stopniami swobody (d1, d2) wynosi:
μ = d2 / (d2 - 2) gdzie d2> 2
Tam, gdzie zauważono, że, co ciekawe, średnia nie zależy od stopni swobody d1 licznika.
Z drugiej strony tryb zależy od d1 i d2 i jest określony wzorem:
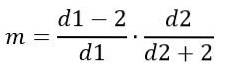
Dla d1> 2.
Wariancja σdwa rozkładu F oblicza się z całki:
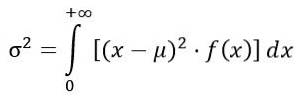
Uzyskanie:
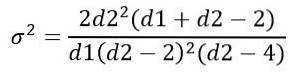
Podobnie jak w przypadku innych ciągłych rozkładów prawdopodobieństwa, które obejmują skomplikowane funkcje, obsługa rozkładu F odbywa się za pomocą tabel lub oprogramowania..
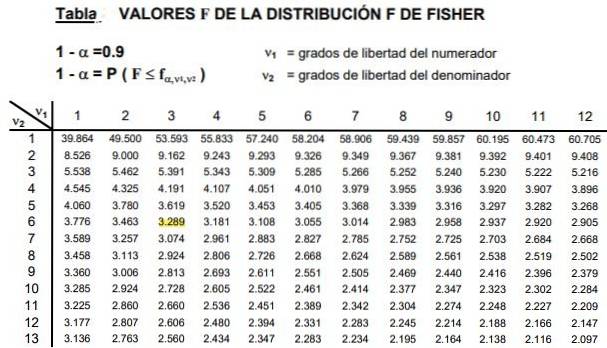
Tabele obejmują dwa parametry lub stopnie swobody rozkładu F, kolumna wskazuje stopień swobody licznika, a wiersz stopień swobody mianownika.
Rysunek 2 przedstawia przekrój tabeli rozkładu F dla przypadku a poziom istotności 10%, czyli α = 0,1. Wartość F jest podświetlona, gdy d1 = 3 i d2 = 6 z poziom zaufania 1- α = 0,9 czyli 90%.
Jeśli chodzi o oprogramowanie obsługujące dystrybucję F, istnieje duża różnorodność, od takich arkuszy kalkulacyjnych Przewyższać do pakietów specjalistycznych, takich jak minitab, SPSS Y R aby wymienić niektóre z najbardziej znanych.
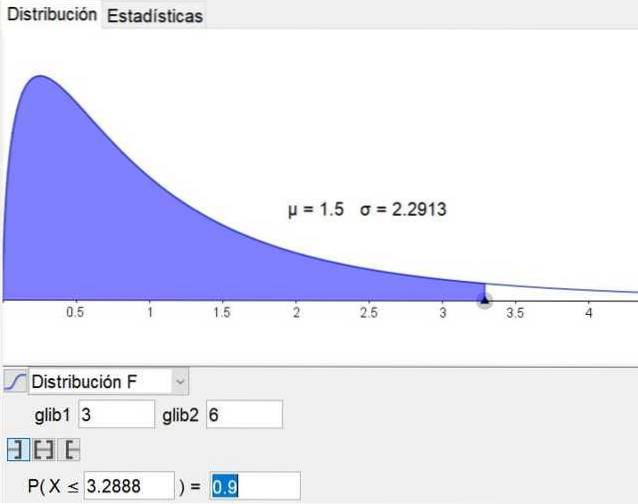
Warto zauważyć, że oprogramowanie do geometrii i matematyki geogebra ma narzędzie statystyczne, które zawiera główne rozkłady, w tym rozkład F. Rysunek 3 przedstawia rozkład F dla przypadku d1 = 3 i d2 = 6 przy poziom zaufania 90%.
Rozważ dwie próbki populacji, które mają taką samą wariancję populacji. Jeżeli próbka 1 ma wielkość n1 = 5, a próbka 2 ma wielkość n2 = 10, określ teoretyczne prawdopodobieństwo, że iloraz ich odpowiednich wariancji jest mniejszy lub równy 2.
Należy pamiętać, że statystyka F definiowana jest jako:
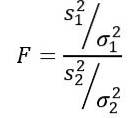
Ale powiedziano nam, że wariancje populacji są równe, więc w tym ćwiczeniu stosuje się następujące zasady:
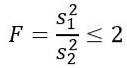
Ponieważ chcemy poznać teoretyczne prawdopodobieństwo, że ten iloraz wariancji próbki jest mniejszy lub równy 2, musimy znać obszar pod rozkładem F między 0 a 2, który można uzyskać za pomocą tabel lub oprogramowania. W tym celu należy wziąć pod uwagę, że wymagany rozkład F ma d1 = n1 - 1 = 5 - 1 = 4 i d2 = n2 - 1 = 10 - 1 = 9, czyli rozkład F ze stopniami swobody ( 4, 9).
Korzystając z narzędzia statystycznego geogebra Określono, że obszar ten wynosi 0,82, stąd wyciągnięto wniosek, że prawdopodobieństwo, że iloraz wariancji próby jest mniejszy lub równy 2, wynosi 82%.
Istnieją dwa procesy produkcyjne dla cienkich arkuszy. Zmienność grubości powinna być jak najmniejsza. Z każdego procesu pobieranych jest 21 próbek. Próbka z procesu A ma odchylenie standardowe 1,96 mikrona, podczas gdy próbka z procesu B ma odchylenie standardowe 2,13 mikrona. Który z procesów ma najmniejszą zmienność? Użyj poziomu odrzucenia 5%.
Dane są następujące: Sb = 2,13 przy nb = 21; Sa = 1,96 przy na = 21. Oznacza to, że musimy pracować z rozkładem F równym (20, 20) stopni swobody.
Hipoteza zerowa oznacza, że wariancja populacyjna obu procesów jest identyczna, to znaczy σa ^ 2 / σb ^ 2 = 1. Hipoteza alternatywna oznaczałaby różne wariancje populacji.
Następnie, przy założeniu identycznych wariancji populacji, obliczona statystyka F jest definiowana jako: Fc = (Sb / Sa) ^ 2.
Ponieważ poziom odrzucenia został przyjęty jako α = 0,05, to α / 2 = 0,025
Rozkład F (0,025, 20,20) = 0,406, natomiast F (0,975, 20,20) = 2,46.
Dlatego hipoteza zerowa będzie prawdziwa, jeśli obliczone F spełnia: 0,406≤Fc≤2,46. W przeciwnym razie hipoteza zerowa zostaje odrzucona.
Ponieważ Fc = (2,13 / 1,96) ^ 2 = 1,18, stwierdza się, że statystyka Fc znajduje się w zakresie akceptacji hipotezy zerowej z pewnością 95%. Innymi słowy, z 95% pewnością oba procesy produkcyjne mają tę samą wariancję populacji..



Jeszcze bez komentarzy