Plik ranga, w statystyce odległość lub amplituda to różnica (odejmowanie) między wartością maksymalną a minimalną zestawu danych z próby lub populacji. Jeśli zakres jest reprezentowany przez literę R, a dane przez x, wzór na zakres to po prostu:
R = xmax - xmin
Gdzie xmax to maksymalna wartość danych, a xmin to minimum.
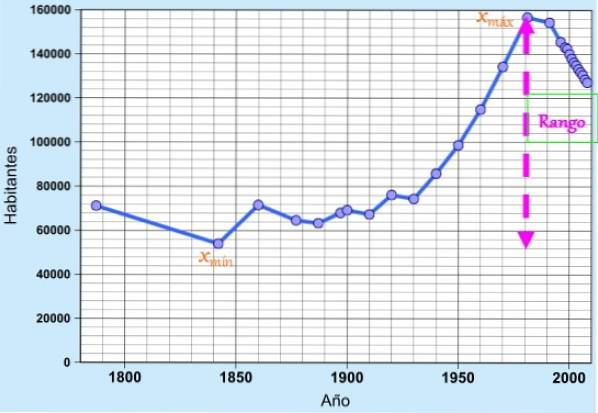
Pojęcie to jest bardzo przydatne jako prosta miara dyspersji, aby szybko ocenić zmienność danych, ponieważ wskazuje na wydłużenie lub długość przedziału, w którym się one znajdują..
Załóżmy na przykład, że mierzy się wzrost grupy 25 studentów pierwszego roku inżynierii na uniwersytecie. Najwyższy uczeń w grupie ma 1,93 m, a najniższy 1,67 m. Są to skrajne wartości przykładowych danych, dlatego ich ścieżka wygląda następująco:
R = 1,93 - 1,67 m = 0,26 m lub 26 cm.
Wzrost uczniów w tej grupie rozkłada się w tym zakresie.
Indeks artykułów
Zakres jest, jak powiedzieliśmy wcześniej, miarą rozłożenia danych. Mały zakres wskazuje, że dane są mniej więcej zbliżone, a rozrzut jest niewielki. Z drugiej strony większy zakres wskazuje, że dane są bardziej rozproszone..
Zalety obliczania zakresu są oczywiste: jest bardzo proste i szybkie do znalezienia, ponieważ jest to prosta różnica.
Ma również te same jednostki, co dane, z którymi pracuje, a koncepcja jest bardzo łatwa do zinterpretowania dla każdego obserwatora..
Na przykładzie wzrostu studentów inżynierii, gdyby zakres wynosił 5 cm, powiedzielibyśmy, że wszyscy uczniowie są w przybliżeniu tej samej wielkości. Ale przy zakresie 26 cm od razu zakładamy, że w próbce są uczniowie wszystkich średnich wysokości. Czy to założenie jest zawsze słuszne?
Jeśli przyjrzymy się uważnie, może się okazać, że w naszej próbie 25 studentów inżynierii tylko jeden z nich mierzy 1,93, a pozostałych 24 ma wysokość bliską 1,67 m..
A jednak zasięg pozostaje ten sam, chociaż jest zupełnie odwrotnie: wysokość większości to ok. 1,90 m, a tylko jedna to 1,67 m..
W obu przypadkach rozkład danych jest zupełnie inny.
Wadą zasięgu jako miary dyspersji jest to, że używa on tylko wartości ekstremalnych i ignoruje wszystkie inne. Ponieważ większość informacji zostaje utracona, nie masz pojęcia, w jaki sposób rozprowadzane są przykładowe dane.
Inną ważną cechą jest to, że zakres próbki nigdy się nie zmniejsza. Jeśli dodamy więcej informacji, to znaczy rozważymy więcej danych, zakres zwiększa się lub pozostaje taki sam.
W każdym razie jest to przydatne tylko podczas pracy z małymi próbkami, nie zaleca się jego wyłącznego stosowania jako miary dyspersji w dużych próbkach..
To, co musisz zrobić, jest uzupełnieniem obliczeniem innych miar dyspersji, które uwzględniają informacje zawarte w danych całkowitych: trasa międzykwartyl, wariancja, odchylenie standardowe i współczynnik zmienności.
Zdaliśmy sobie sprawę, że słabość zakresu jako miary rozproszenia polega na tym, że wykorzystuje on tylko skrajne wartości rozkładu danych, pomijając pozostałe..
Aby uniknąć tej niedogodności, rozszerzenie kwartyle: trzy wartości znane jako pomiary położenia.
Dystrybuują niezgrupowane dane na cztery części (inne szeroko stosowane miary pozycji to decylach i percentyle). Oto jego cechy:
-Pierwszy kwartyl Q1 jest taką wartością danych, że 25% z nich jest mniejsze niż Q1.
-Drugi kwartyl Qdwa jest mediana rozkładu, co oznacza, że połowa (50%) danych jest mniejsza od tej wartości.
-Wreszcie trzeci kwartyl Q3 zwraca uwagę, że 75% danych jest mniejszych niż Q3.
Następnie przedział międzykwartylowy lub przedział międzykwartylowy definiuje się jako różnicę między trzecim kwartylem Q3 a pierwszy kwartyl Q1 danych:
Przedział międzykwartylowy = RQ = Q3 - Q1
W ten sposób wartość zakresu RQ nie są tak dotknięte przez wartości ekstremalne. Z tego powodu zaleca się używanie go w przypadku przekrzywionych rozkładów, na przykład opisanych powyżej u bardzo wysokich lub bardzo niskich uczniów..
Istnieje kilka sposobów ich obliczenia, tutaj zaproponujemy jeden, ale w każdym przypadku konieczna jest znajomość numer zamówienia „Nlub”, Czyli miejsce, które zajmuje odpowiedni kwartyl w rozkładzie.
To znaczy, jeśli na przykład termin odpowiadający Q1 jest drugą, trzecią lub czwartą częścią rozkładu.
Nlub (Q1) = (N + 1) / 4
Nlub (Qdwa) = (N + 1) / 2
Nlub (Q3) = 3 (N + 1) / 4
Gdzie N to liczba danych.
Mediana to wartość znajdująca się w środku rozkładu. Jeśli liczba danych jest nieparzysta, nie ma problemu z jej znalezieniem, ale jeśli jest parzysta, dwie wartości środkowe są uśredniane, aby uzyskać jedynkę.
Po obliczeniu numeru zamówienia przestrzegana jest jedna z trzech zasad:
-Jeśli nie ma miejsc po przecinku, przeszukiwane są dane wskazane w rozkładzie i to będzie przeszukiwany kwartyl.
-Gdy numer zamówienia jest w połowie między dwoma, dane wskazane przez część całkowitą są uśredniane z następującymi danymi, a wynik jest odpowiednim kwartylem.
-W każdym innym przypadku jest zaokrąglana do najbliższej liczby całkowitej i będzie to pozycja kwartylu.
W skali od 0 do 20 grupa 16 studentów matematyki I uzyskała z egzaminu śródokresowego następujące oceny (punkty):
16, 10, 12, 8, 9, 15, 18, 20, 9, 11, 1, 13, 17, 9, 10, 14
Odnaleźć:
a) Zakres lub zakres danych.
b) Wartości kwartyli Q1 i Q3
c) Rozstęp międzykwartylowy.

Pierwszą rzeczą, jaką należy zrobić, aby znaleźć ścieżkę, jest uporządkowanie danych w kolejności rosnącej lub malejącej. Na przykład w rosnącym porządku masz:
1, 8, 9, 9, 9, 10, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20
Stosując wzór podany na początku: R = xmax - xmin
R = 20-1 punktów = 19 punktów.
Zgodnie z wynikiem kwalifikacje te są bardzo rozproszone.
N = 16
Nlub (Q1) = (N + 1) / 4 = (16 + 1) / 4 = 17/4 = 4,25
Jest to liczba z miejscami dziesiętnymi, której część całkowita to 4. Następnie przechodzimy do rozkładu, szukamy danych zajmujących czwarte miejsce i ich wartość jest uśredniana z wartością z pozycji piątej. Ponieważ oba mają po 9, średnia wynosi również 9, więc:
Q1 = 9
Teraz powtarzamy procedurę, aby znaleźć Q3:
Nlub (Q3) = 3 (N + 1) / 4 = 3 (16 + 1) / 4 = 12,75
Ponownie jest to ułamek dziesiętny, ale ponieważ nie jest to połowa, jest zaokrąglana do 13. Kwartyl, którego szukamy, zajmuje trzynastą pozycję i jest następujący:
Q3 = 16
RQ = Q3 - Q1 = 16 - 9 = 7 punktów.
Który, jak widzimy, jest znacznie mniejszy niż zakres danych obliczony w sekcji a), ponieważ minimalny wynik wynosił 1 punkt, wartość znacznie bardziej od reszty..


Jeszcze bez komentarzy